
Large Language Models (LLMs) have revolutionized the way we access and understand information. These advanced AI systems are trained on vast amounts of data, which allows them to recognize patterns and meaning in language. By understanding words in context, they make it easier to explore ideas, learn new things, and find answers quickly and efficiently. LLM is shaping a new era in how we interact with and use information in everyday life.
Early traditional LLMs relied solely on provided knowledge from their static training data. This limitation often leads to hallucination, where the model generates incorrect or fabricated information due to outdated or incomplete data. Recognizing these issues, the concept of Retrieval-Augmented Generation (RAG) was introduced.
# Retrieval-Augmented Generation (RAG)
The idea behind Retrieval-Augmented Generation (RAG) (opens new window) was to supply a reliable database to LLMs to enhance their response quality. Instead of relying solely on the information they learned during training, RAG enables LLMs to access real-time data by using a vector database (opens new window) like MyScale (opens new window) as a knowledge base.
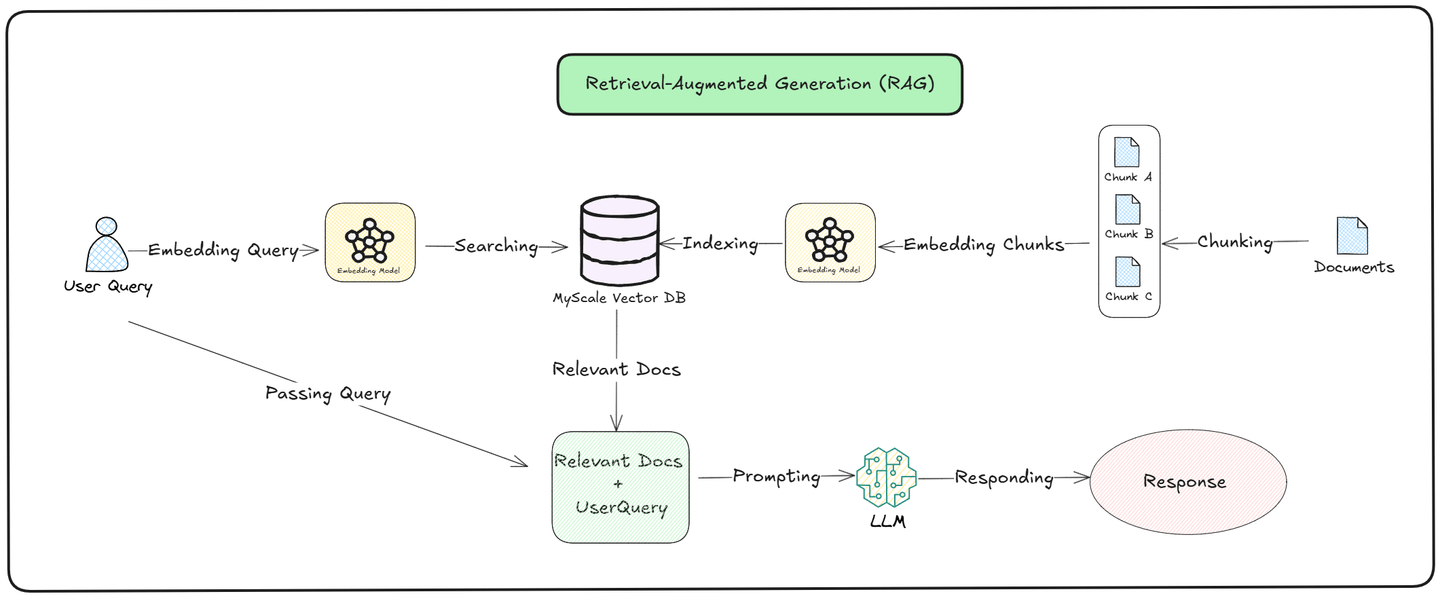
As we can see in the above illustration, the query process is devided into two parts, which are retrieval (opens new window) and generation: (opens new window)
Retrieval: The model searches an external Knowledge Base for relevant documents. It converts the user's query into a vector and compares it to the stored data. The most similar documents are retrieved and ranked based on relevance to the query, ensuring that the model pulls in accurate and up-to-date information.
Generation: After retrieving the relevant documents, the model uses both the retrieved information and its pre-trained knowledge to create a response. It combines the newly found data with what it already knows to generate an answer that is contextually accurate and relevant to the user's question.
No doubt, RAG improves the accuracy and quality of responses. However, its pipeline operates in a static way. Each time a user makes a query, the same process is followed: relevant information is retrieved from the vector database and given to the LLM to generate a response. This consistency ensures reliability but limits the system’s ability to adapt dynamically to specific contexts or scenarios.
To overcome the limits of RAG's static pipeline, new methods like ReACT (Reasoning and Acting) (opens new window)) and agents (opens new window) have been introduced. These tools help systems respond better to user queries by adding:
- Reasoning
- Decision-making
- Task execution.
They are the building blocks for advanced systems like Agentic RAG, which mix logical thinking with simple actions to make things more accurate and flexible.
# What is ReACT
ReACT, which means "Reasoning and Acting," is a breakthrough in how LLMs work. Unlike traditional models that give quick answers, ReACT helps AI think through problems step by step. This approach, called chain-of-thought (CoT), allows models to solve complex tasks more effectively.
In a 2022 research paper, Yao and team showed how combining reasoning with action can make AI smarter. Traditional models often struggle with complicated problems, but ReACT changes that. It helps AI pause, think critically, and develop better solutions.
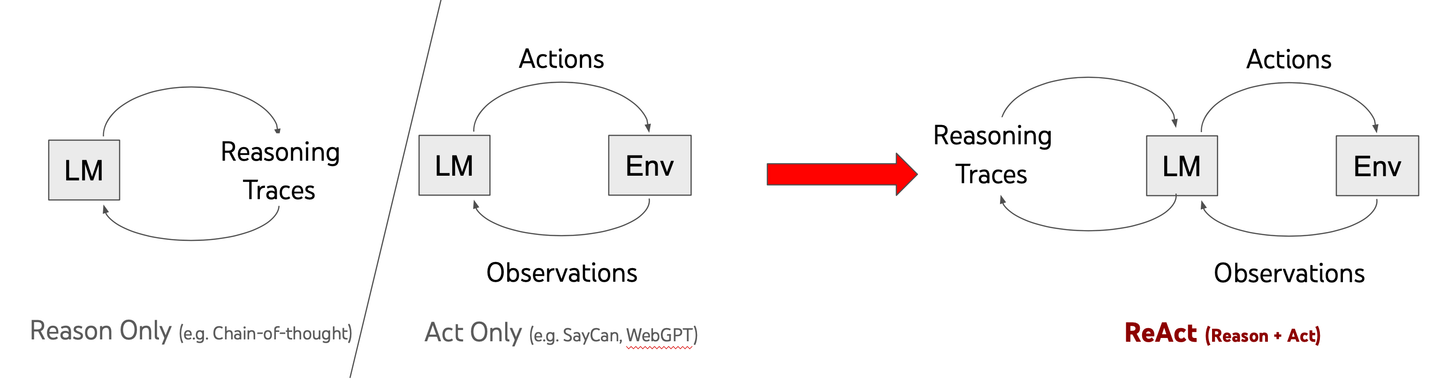
The key difference is in the problem-solving approach. Instead of rushing to an answer, ReACT-powered models break down challenges methodically. This makes them more adaptable and reliable when tackling real-world issues.
By teaching AI to reason before acting, ReACT is pushing the boundaries of what artificial intelligence can do. It's not just about having information—it's about using that information intelligently.
# How ReACT Works
ReACT enhances the capabilities of LLMs by integrating a systematic reasoning process with actionable steps. The framework operates through the following stages:

Query Analysis: The model starts by breaking down the user’s query into manageable components.
Chain of Thought Reasoning: The LLM reasons step-by-step, analyzing each component and determining the actions required. For instance, it may retrieve information, cross-check data, or combine multiple sources logically.
Action Execution: Based on its reasoning, the model takes actions such as interacting with external tools, retrieving specific data, or re-evaluating the query as new information becomes available.
Iterative Improvement: ReACT can refine its reasoning as it progresses through the steps, dynamically adjusting based on intermediate outcomes.
This step-by-step reasoning is akin to how humans solve complex problems, ensuring that the final response is well-thought-out and contextually relevant. For example, if a query asks, "What are the key differences between ReACT and agents?" the model first identifies the components (e.g., defining ReACT, defining agents) and then reasons through them sequentially before synthesizing a complete answer.
# Introducing Agents
While ReACT focuses on reasoning within the LLM, agents take on the role of executing specific tasks outside the model. Agents are autonomous entities that act on instructions provided by the LLM, enabling the system to interact with external tools, APIs, databases, or even perform complex multi-step workflows.
# How Agents Work
- Task Identification: The LLM, often guided by ReACT reasoning, determines which agent is needed for a given task. For example, a query about recent weather conditions might activate a data retrieval agent to fetch real-time weather updates.
- Execution: The selected agent carries out the task. This could involve querying a database, scraping web content, calling an API, or performing calculations.
- Feedback Loop: Once the task is completed, the agent returns the result to the LLM for further reasoning or response generation.
- Chaining Multiple Agents: In more complex scenarios, multiple agents can be orchestrated in a sequence. For instance, one agent retrieves raw data, another agent processes it, and a third agent visualizes or formats the final output.
# Agents and Modularity
Agents are modular by design, meaning they can be customized for different applications. Examples include:
- Retrieval Agents: Fetch data from vector databases or knowledge graphs.
- Summarization Agents: Condense retrieved information into key points.
- Computation Agents: Handle tasks requiring calculations or data transformations.
- API Interaction Agents: Integrate with external services to fetch real-time updates.
This modular approach allows for flexibility and scalability, as new agents can be added to meet specific requirements.
# What is Agentic RAG
Agentic RAG combines the reasoning capabilities of ReACT with the task execution power of agents, creating a dynamic and adaptive system. Unlike traditional RAG, which follows a fixed pipeline, Agentic RAG introduces flexibility by using ReACT to orchestrate agents dynamically based on the context of the user query. This allows the system not only to retrieve and generate information but also to take informed actions based on the context, evolving goals, and the data it interacts with.
These advancements make Agentic RAG a far more powerful and flexible framework. The model is no longer limited to passively reacting to user queries; instead, it can actively plan, execute, and adapt its approach to solve problems independently. This enables the system to handle more intricate tasks, adjust dynamically to new challenges, and deliver more contextually accurate responses.
# How Agentic RAG Works
The key innovation in Agentic RAG lies in its ability to autonomously use tools, make decisions, and plan its next steps. The pipeline follows these core stages:
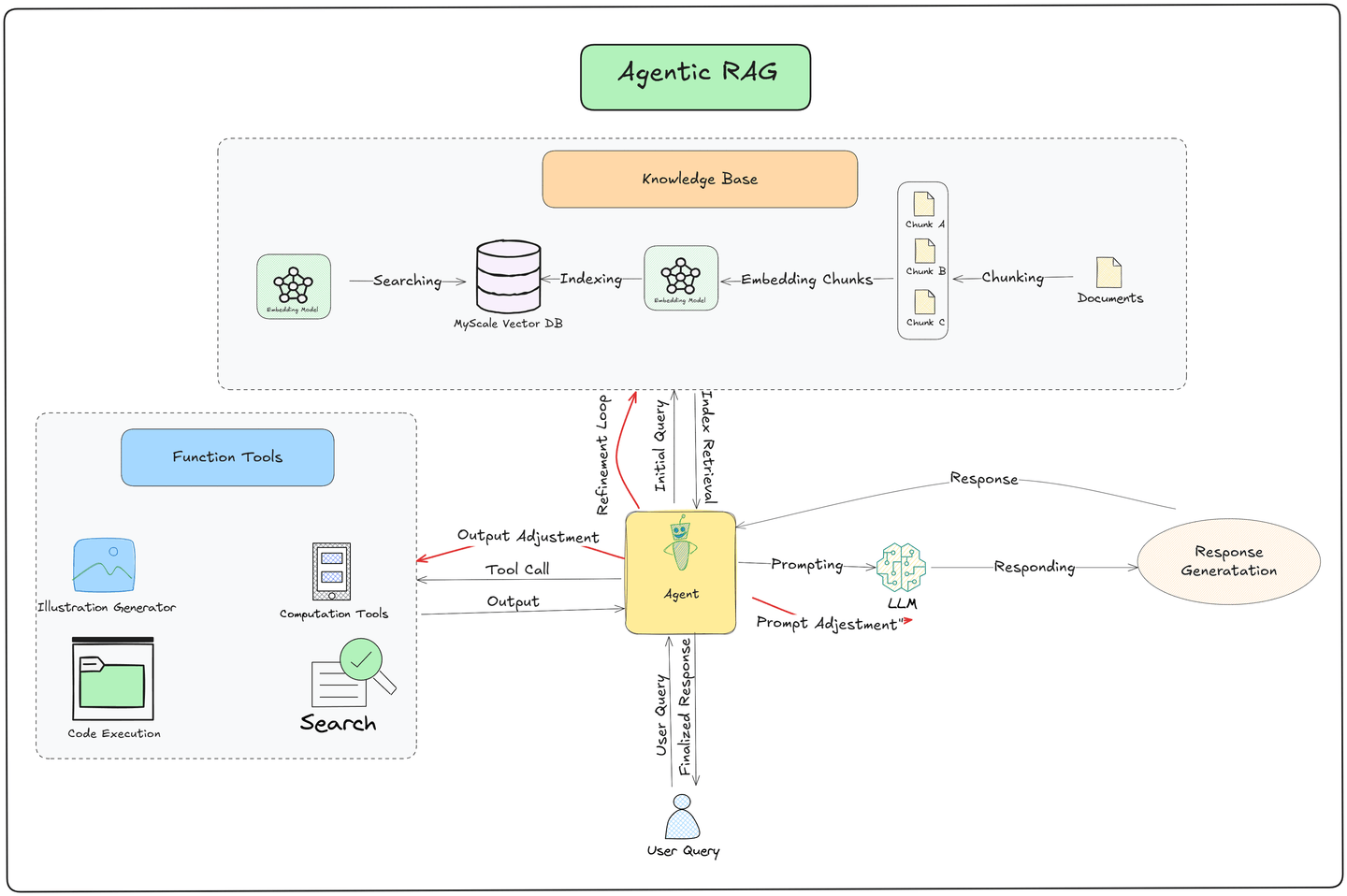
- User Query Submission:
- The process begins with the user submitting a query to the system. This query acts as a trigger for the pipeline.
- Data Retrieval from a Vector Database:
- An Agent searches a Vector Database, where documents are stored as embeddings, ensuring efficient and quick retrieval of relevant information.
- If the retrieved data is insufficient, the agent refines the query and performs additional retrieval attempts to extract better results.
- External Data Sourcing with Function Tools:
- If the Vector Database lacks the necessary information, the agent uses Function Tools to gather real-time data from external sources like APIs, web search engines, or proprietary data streams. This ensures the system provides up-to-date and contextually relevant information.
- Large Language Model (LLM) Response Generation:
- The retrieved data is passed to the LLM, which synthesizes it to generate a detailed, context-aware response tailored to the query.
- Agent-Driven Refinement:
- After the LLM produces a response, the agent refines it further for accuracy, relevance, and coherence before delivering it to the user.
# Comparison: Agentic RAG vs RAG
Here is the comparison table.
| Feature | RAG (Retrieval-Augmented Generation) | Agentic RAG |
|---|---|---|
| Task Handling | Retrieves relevant information from external sources (e.g., databases, documents) before generating responses. | Extends RAG by adding reasoning and action capabilities, enabling active interaction with the environment and feedback learning. |
| Environment Interaction | Retrieves data from external sources. | Actively interacts with external environments (APIs, data sources) and adapts based on feedback. |
| Reasoning | No explicit reasoning; relies on retrieval to provide context. | Explicit reasoning traces guide decision-making and task completion. |
| Feedback Loop | Does not incorporate feedback loops for learning. | Incorporates feedback from the environment to refine reasoning and actions. |
| Autonomy | Passive; the system only responds after retrieving data. | Active autonomy in reasoning and action, making decisions and learning dynamically. |
| Use Case | Ideal for tasks needing contextual retrieval (e.g., question answering). | Suitable for tasks requiring both reasoning and interaction with external systems (e.g., decision-making, planning). |
# Conclusion
In conclusion, Agentic RAG represents a significant advancement in the field of AI. By combining the power of large language models with the ability to autonomously reason and retrieve information, Agentic RAGs offer a new level of intelligence and adaptability. As AI continues to evolve, Agentic RAGs will play an increasingly important role in various industries, transforming the way we work and interact with technology.
To fully realize the potential of Agentic AI, a robust and efficient vector database is essential like the MyScale Vector Database (opens new window), which is primarily designed to meet the demanding needs of large-scale AI applications. With its advanced indexing techniques and optimized query processing capabilities, MyScale empowers Agentic RAG systems to retrieve relevant information and generate high-quality responses quickly. Leveraging the power of MyScale can unlock the full potential of Agentic AI and drive innovation.



