
Vector databases are explicitly designed to store and manage vector data, playing a crucial role in many AI applications, such as semantic text search and image search. While traditional term matching and BM25 algorithms still hold significance in text retrieval, the widely adopted Elasticsearch system has recently added vector search capabilities. Notably, MyScaleDB, an open-source, high-performance SQL vector database, has also introduced full-text search (opens new window) recently. In this article, we demonstrate that MyScaleDB rivals Elasticsearch in full-text search performance while achieving lower latency and utilizing 40% less memory. Furthermore, when incorporating vector search, MyScale achieves up to 10x higher performance while consuming only 12% of the cost. With its high performance, low cost, and a rich SQL ecosystem based on ClickHouse, MyScaleDB emerges as an efficient and powerful upgrade and alternative to Elasticsearch.
# What is Elasticsearch
Elasticsearch is a distributed, RESTful search and analytics engine built on Apache Lucene. It can quickly store, search, and analyze large amounts of data and is widely used in areas such as log analyses, application searches, security analyses, and business analyses.
Elasticsearch has the following advantages:
- Powerful Search Capabilities: Elasticsearch provides powerful full-text search capabilities, including exact value, full-text, and vector searches, as well as complex query, filter, and aggregation operations, allowing users to retrieve the desired information quickly and accurately.
- Rich Features: Elasticsearch offers rich features and flexible configuration options, such as text analysis, aggregation analysis, and geospatial search, to meet a wide variety of search and analysis needs.
- Rich Ecosystem: The Elasticsearch ecosystem is vast. It includes various plugins, tools, and third-party integrations that extend its functionality and application scenarios, providing users with more choices and flexibility.
- Distributed Architecture: As a distributed system, Elasticsearch can easily scale up to many nodes, achieving high availability and horizontal scalability, making it suitable for large-scale data processing and analysis tasks.
- Real-time Data Processing: Elasticsearch supports indexing and searching real-time data, allowing it to quickly process large amounts of real-time data and provide instant query results.
However, Elasticsearch still has several shortcomings, including:
- Steep Learning Curve: Elasticsearch has a relatively steep learning curve, especially for beginners, requiring time to grasp its complex concepts and usage methods.
- Limited Vector Retrieval Algorithms: As of version 8.13, Elasticsearch has limited support for vector retrieval algorithms, such as brute-force kNN and Approximate kNN based on HNSW. This limits its application in complex vector retrieval scenarios.
- High Resource Consumption: Due to its powerful features and distributed architecture, Elasticsearch requires relatively high resources at runtime, including memory, CPU, and storage space.
In summary, Elasticsearch is a powerful tool in the field of text retrieval. Still, it has some shortcomings in usability, vector retrieval, and resource utilization, which limit its application in complex AI retrieval and analysis scenarios.
# Preferred Elasticsearch Alternative: MyScaleDB
MyScaleDB is built on the open-source SQL columnar storage database ClickHouse. It features a self-developed high-performance and high-data-density vector indexing algorithm. We have undergone deep research and optimization in its retrieval capabilities and storage engines for SQL and vector joint queries, making MyScaleDB the world’s first SQL vector database product that significantly surpasses dedicated vector databases in terms of comprehensive performance and cost-effectiveness.
# Native Compatibility with SQL and Vector
Users interact with MyScaleDB using SQL, lowering the barriers to entry, and reducing the learning curve so that they can start quickly and ramp up easily. MyScaleDB offers a flexible data model and query language, supporting users in customizing data processing and analysis strategies according to their specific needs—and improving application flexibility and execution efficiency. Combining SQL and vectors in complex AI application scenarios gives developers a more intuitive and efficient development method, significantly increasing developer efficiencies.
Unlike Elasticsearch’s Domain Specific Language (DSL), which is based on JSON queries, users only need to master the vector retrieval distance() function for using MyScaleDB. They can develop complex vector retrieval queries with this information and their existing SQL knowledge. Moreover, they can also perform complex analyses and data processing at a database level, speeding up the overall processing efficiency of the application system.
For instance:
-- Perform vector search and return top 10 results
SELECT
id, title, text
distance(vector, query_vector) as dist
FROM doc_table
ORDER BY
dist ASC
LIMIT 10;
# Replacing Elasticsearch with Text Search Capabilities
In the latest version, MyScaleDB has introduced powerful features such as full-text and hybrid search, providing practical solutions for handling complex AI requirements and data challenges now—and in the future. It embeds the Tantivy full-text search engine library, featuring fast index construction, efficient searching, and multithreading support. On top of it all, it is super easy to use, vastly flexible, and highly suitable for quickly retrieving large-scale text data. This allows users to quickly search text data stored in the database and return the result set that is the closest match—according to the BM25 scores.
For example, the following table contains the results of a text search capabilities test we ran on the same dataset, “wiki” (560 million records). MyScaleDB’s P95 query latency is significantly reduced, and there is also a noticeable decrease in memory usage. Thus, in the context of full-text search and in terms of functionality, MyScaleDB can effectively replace Elasticsearch.
| Engine | Function | QPS | p95 Latency | Peak Memory |
|---|---|---|---|---|
| MyScaleDB | TextSearch | 4099.16 | 4.563ms | 2.35GB |
| ElasticSearch | match | 3907 | 8.863ms | 3.7GB |
| ElasticSearch | wildcard | 4679.16 | 5.583ms | 3.7GB |
# Outperforming Elasticsearch with Vector Search Capabilities
MyScaleDB utilizes vector retrieval technology and supports various vector indexing algorithms, including MTSG, SCANN, FLAT, and the HNSW and IVF families. This better meets the retrieval needs of various AI scenarios and has an absolute advantage in processing large-scale high-dimensional data.
Using a large-scale dataset (LAION 5M vectors, 768 dimensions), MyScaleDB and Elasticsearch's performance in vector search under different concurrent query threads was tested. The results of the accuracy and throughput tests are shown in the figure below.
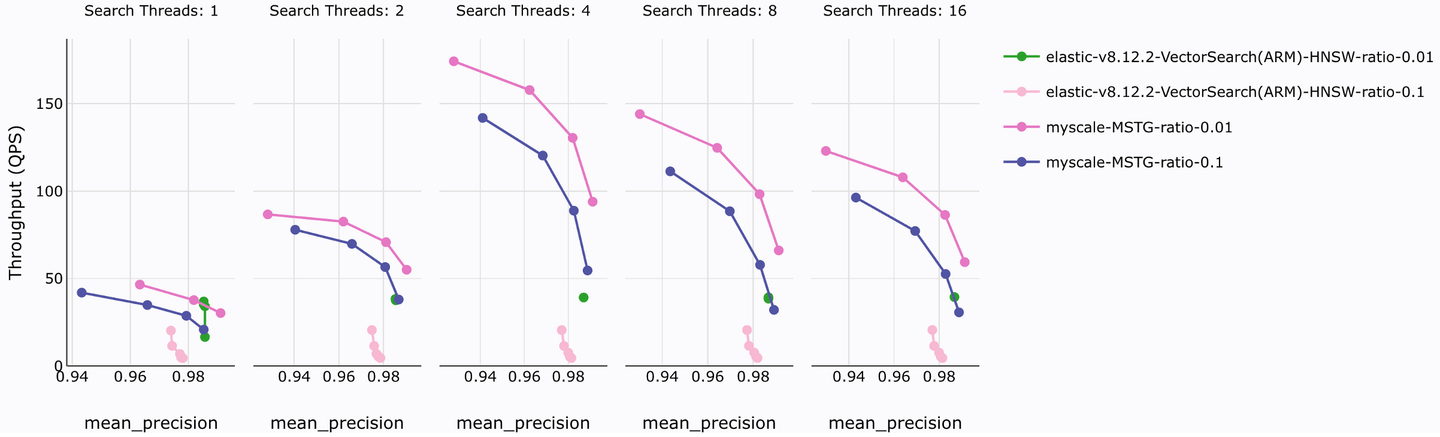
This test tested two common filtering ratios, 0.1 and 0.01. An analysis of the results shows, under similar accuracy, MyScaleDB's MSTG index demonstrates up to 10x QPS performance improvement. MyScaleDB has similar advantages in terms of index resource consumption, creation time, query latency, and query cost.
More notably, MyScaleDB SaaS only costs $120 per month to serve 5 million vectors, while ElasticCloud is more than eight times as expensive at $982. Furthermore, MyScaleDB supports multiple types of vector indexes and, combined with its powerful retrieval performance and cost-effective usage costs, is more suitable for vector retrieval and analysis query scenarios than Elasticsearch.
You can refer to the MyScaleDB Vector Database Benchmark (opens new window) for more performance test results.
# Cost-Effective Use of Resources
As described above, MyScaleDB is built on the high-performance columnar database ClickHouse, currently the fastest and most resource-efficient open-source database for real-time applications and analytics. Some of ClickHouse’s advanced features made it a good choice, including efficient indexing mechanism, data compression technology, columnar storage structure, vectorized query execution, and distributed processing capabilities.
Moreover, MyScaleDB’s query engine is optimized for modern CPUs and memory. It uses vectorized query processing and data parallel processing techniques to fully leverage the performance of multi-core processors, accelerating data calculations. Inheriting ClickHouse’s columnar storage model, MyScaleDB achieves efficient data compression and fast column-level operations. It can read only the columns specified in the query, reducing data read volume, improving data compression rates, and reducing storage costs, making it particularly suitable for analyzing and processing massive amounts of data.
In summary, by combining vector retrieval technology, the full-text search engine, Tantivy, ClickHouse’s high-performance features, distributed architecture, and optimized query engine, MyScaleDB achieves efficient processing and analysis of large-scale datasets. It is especially suited for complex data analysis, hybrid search, full-text search, and vector retrieval scenarios.
# How to Replace Elasticsearch with MyScaleDB
This process involves tasks such as data modeling, data migration, and query logic conversion. Refer to the Quickstart (opens new window) guide for more information on quickly spinning up a MyScaleDB cluster, importing data, and executing SQL queries.
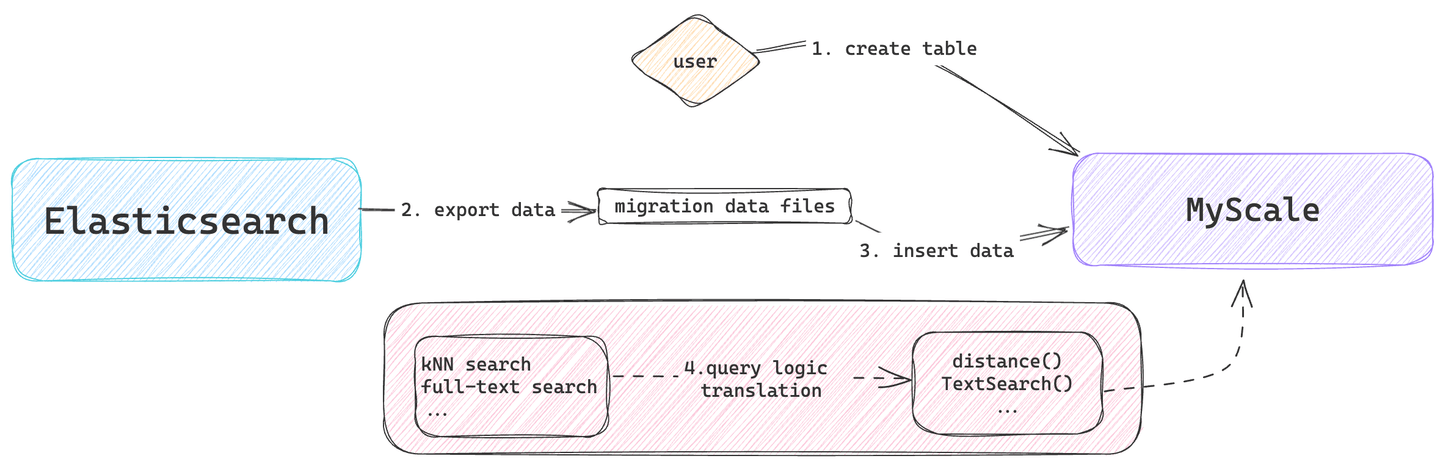
# Data Model Design
The data model design phase involves determining how to map the document model in Elasticsearch to the table structure in MyScaleDB. It primarily defines the columns, data types, and index types for the migrating data tables in MyScaleDB.
# Data Type Conversion
MyScaleDB is compatible with all ClickHouse’s data types; therefore, all field data types in Elasticsearch have corresponding data types in MyScaleDB.
Note:
The dense_vector type used for vector search in Elasticsearch should be mapped to Array(Float32) or FixedString in MyScaleDB based on the element_type. Secondly, the corresponding length constraint should be added to the column accordingly.
# Vector Index Definition
MyScaleDB supports multiple types of vector indexes. However, we strongly recommend using MSTG indexes for optimal performance.
Refer to the vector query tutorial (opens new window) for information on creating and operating vector indexes for accelerated vector search.
Here is an example that converts the image-index in Elasticsearch to the es_data_migration table in MyScaleDB:
{
"image-index": {
"mappings": {
"properties": {
"file-type": {
"type": "keyword"
},
"image-vector": {
"type": "dense_vector",
"dims": 3,
"index": true,
"similarity": "l2_norm"
},
"title": {
"type": "text"
},
"title-vector": {
"type": "dense_vector",
"dims": 5,
"index": true,
"similarity": "l2_norm"
}
}
}
}
}
CREATE TABLE default.es_data_migration
(
`id` UInt32,
`file_type` String,
`image_vector` Array(Float32),
`title` String,
`title_vector` Array(Float32),
VECTOR INDEX vec_ind_image image_vector TYPE MSTG('metric_type=L2'),
VECTOR INDEX vec_ind_title title_vector TYPE MSTG('metric_type=L2'),
CONSTRAINT check_length_image CHECK length(image_vector) = 3,
CONSTRAINT check_length_title CHECK length(title_vector) = 5
)
ENGINE = MergeTree
PRIMARY KEY id;
# Data Migration
This phase mainly involves exporting data from Elasticsearch and its subsequent import into MyScaleDB.
- Export Data from Elasticsearch: Users can export data in common formats (like JSON or CSV) using various methods, such as the Elasticsearch API, Logstash, Kibana’s CSV Reports feature, and the Python es2csv tool.
- Import Data into MyScaleDB: MyScaleDB supports different data import methods including Python client (opens new window), HTTPS interface (opens new window), etc.
For instance, here is an example using Python client to migrate data files exported from Elasticsearch to MyScaleDB:
import clickhouse_connect
import pandas as pd
# initialize client
# For SaaS users, navigate to the MyScaleDB Clusters page, click the Action drop-down link, and select Connection details.
client = clickhouse_connect.get_client(
host='127.0.0.1',
port=8123,
username='default',
password=''
)
def convert_vector(vector_str):
return list(map(float, vector_str.split(', ')))
# read migration data file
data = pd.read_csv('test.csv', usecols=['_id', 'image-vector', 'title', 'title-vector'], converters={'image-vector': convert_vector, 'title-vector': convert_vector})
# insert data into the migration table
client.insert('default.es_data_migration', data.values.tolist(), ['id', 'image_vector', 'title', 'title_vector'])
# Query Logic Translation
The original application's query retrieval logic—initially handled by Elasticsearch—has been changed to a MyScaleDB search, and the corresponding data processing logic has been updated accordingly.
{
"knn": {
"field": "image-vector",
"query_vector": [-5, 9, -12],
"k": 10,
"num_candidates": 100
},
"fields": [ "title", "file-type" ]
}
SELECT
id,
title,
file_type,
distance(image_vector, [-5.0, 9.0, -12.0]) AS l2_dist
FROM default.es_data_migration
ORDER BY l2_dist ASC
LIMIT 10

# Conclusion
Through a comparative analysis of the functionality and performance between MyScaleDB and Elasticsearch, it can be seen that MyScaleDB is not only an efficient replacement for—and upgrade to—Elasticsearch but also an advanced data solution that can adapt to future data needs and technology trends. It has significant advantages, especially in vector search and resource costs.
In addition, based on ClickHouse's powerful distributed storage and processing architecture, MyScaleDB is highly flexible in scalability, allowing it to scale to large clusters to meet growing data demands easily.
Furthermore, MyScaleDB is compatible with ClickHouse's ecosystem components, including abundant documentation resources and extensive community support. It is also integrated with popular developer tools worldwide, such as Python Client (opens new window), Node.js (opens new window), and the LLM framework, including OpenAI (opens new window), LangChain (opens new window), LangChain JS/TS (opens new window), and LlamaIndex (opens new window), providing users with a better user experience and support.
Lastly, MyScaleDB supports a wide range of data types and query syntax, making it adaptable to different data requirements and query scenarios. With its comprehensive SQL data management capabilities, robust data storage, and query capabilities, MyScaleDB will play an increasingly important role in data storage and processing in the future, providing users with richer and more efficient services.




