
The advent of AI Agents (opens new window) has reshaped various industries, offering unparalleled efficiency and productivity gains. Studies show that over 60% (opens new window) of business owners anticipate increased productivity through AI implementation. Specifically, 64% (opens new window) believe that AI will enhance overall business productivity, while 42% expect streamlined job processes. These statistics underscore the transformative impact of AI agents in optimizing workflows and driving growth across sectors.
In everyday life, we encounter AI Agents more than we realize – from virtual assistants (opens new window) like Siri and Alexa to personalized recommendation systems (opens new window) on streaming platforms. These agents play a pivotal role in enhancing user experiences, providing tailored solutions, and automating routine tasks seamlessly.
In the realm of AI development, LangChain (opens new window) stands out as a revolutionary modular framework designed to simplify the creation of AI-powered language applications. This innovative tool provides a standardized interface (opens new window) for interacting with language models and seamless integration with external data sources. LangChain abstracts away the complexities typically associated with working on Large Language Models (LLMs) (opens new window), making it accessible even to those without extensive expertise in machine learning or AI.
# What is a Chain in LangChain?
LangChain was initially developed to provide a seamless interface for integrating LLMs with external data sources. It aims to bridge the gap between the capabilities of powerful AI models and the vast amounts of data they can utilize. This framework allows developers to create advanced applications that leverage the power of LLMs to access and handle data from various sources.
LangChain's structure is primarily based on the concept of "chains." These chains represent sequences of operations that transform inputs into desired outputs. The elegance of LangChain lies in its modularity and flexibility, allowing developers to craft custom workflows tailored to their specific needs.
In LangChain, a chain is a sequence of steps or operations that process input data to produce an output. Each step in the chain performs a specific function, such as data retrieval, transformation, or interaction with an LLM. Chains can be simple, involving just a few steps, or complex, involving multiple stages of data processing and model interactions.
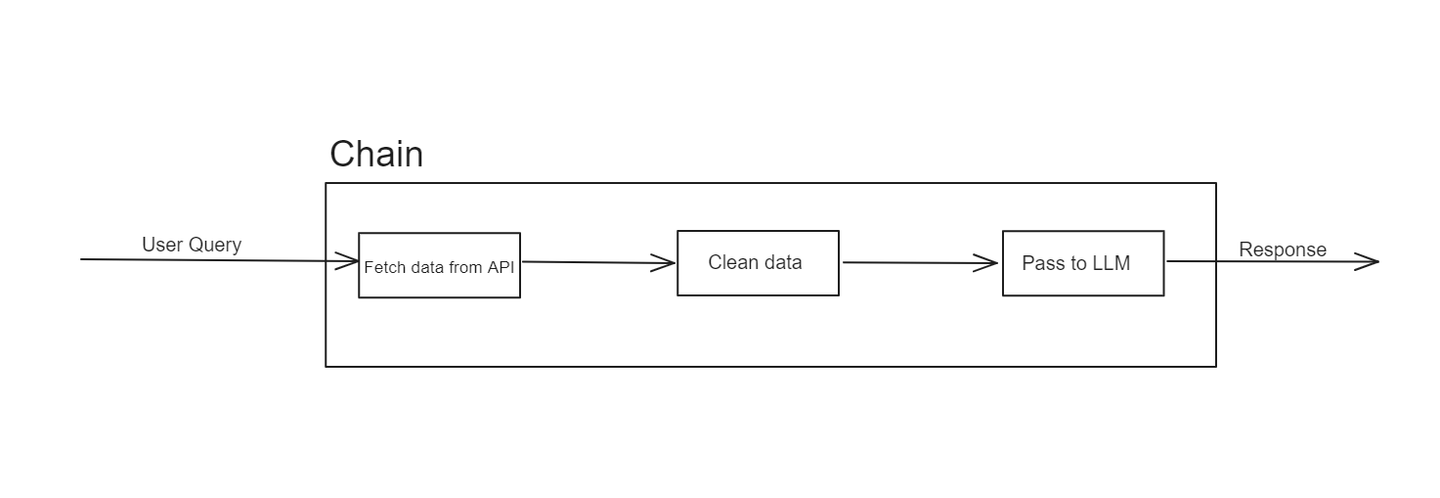
For example, a chain might start with retrieving data from an API, then passing that data through a series of transformations, and finally feeding it into an LLM to generate a response. This modular approach makes it easy to design, test, and reuse individual components of a workflow.
However, chains have their limitations. They are linear and can sometimes struggle with more dynamic or adaptive tasks. This is where LangChain agents come into play, addressing the limitations of chains by offering more flexibility and intelligence.
# What are LangChain Agents?
LangChain agents are powerful components designed to enhance the capabilities of LLMs by enabling them to make decisions and take actions based on those decisions. Unlike chains, which follow a predetermined sequence of actions, agents use LLMs as reasoning engines to dynamically determine the sequence of actions to perform.
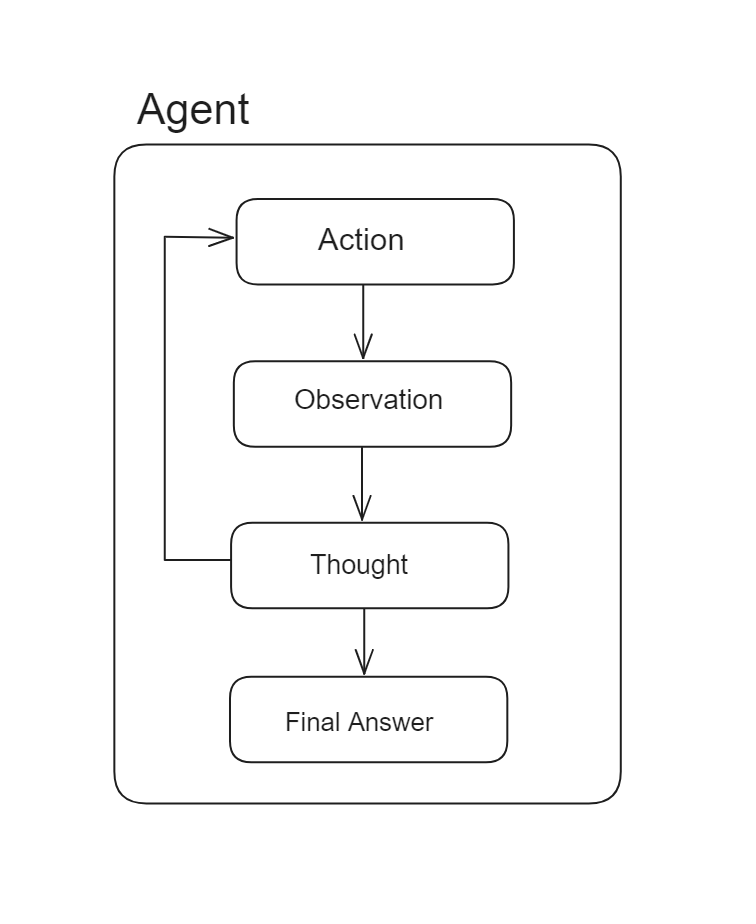
The core functionality of LangChain agents involves selecting and executing actions based on input data and the outcomes of previous actions. This makes them highly adaptable and capable of handling complex tasks with minimal human intervention. For example, an agent might interact with various tools and data sources, process information, and iteratively refine its actions to achieve a specific goal.
In chains, a sequence of actions is hardcoded whereas in agents, the sequence of actions are not pre-determined and a language model is used as a reasoning engine to determine which actions to take and in which order.
Agents have several key qualities:
- Adaptability: Agents can adjust their actions based on the data and context they encounter. This means they are not confined to a predefined sequence of steps like chains.
- Autonomy: Agents can operate independently, making decisions on the fly without needing constant oversight.
- Interactivity: Agents can interact with multiple data sources, tools, and LLMs, making them versatile in handling various tasks.
By incorporating agents, your system can manage more sophisticated workflows that require dynamic responses and adaptive behavior, overcoming the rigidity of simple chains.
# What Are the Major Components of an Agent
To build an effective agent in LangChain, several key components are required:
# Tools
Tools are the building blocks that an agent uses to perform tasks, including interacting with APIs, databases, and data processing functions. Each tool provides specific capabilities that the agent can leverage to accomplish various tasks.
LangChain offers various ways to utilize different tools, including predefined tools, retrievers (opens new window) as tools, and custom tools (opens new window). Let's explore each of these in detail:
# Predefined Tools
LangChain provides a collection of predefined tools (opens new window) that you can readily use by importing them and integrating them into your agents. For example:
from langchain_community.tools import DuckDuckGoSearchRun
search = DuckDuckGoSearchRun()
In this example, we are importing the DuckDuckGoSearchRun tool from the langchain_community.tools module and initializing it. After initialization, this tool can be utilized within an agent via a toolkit (opens new window), as we will see later.
# Using Retrievers as Tools
In scenarios where you need to fetch data from a vector database (opens new window) based on user queries, LangChain allows you to convert data retrievers into tools and use them within your agents. Here’s how you can do it:
from langchain.tools.retriever import create_retriever_tool
retriever_tool = create_retriever_tool(
retriever,
"name_of_the_tool",
"Description of the tool",
)
By using the create_retriever_tool method of LangChain, you can convert any retriever into a LangChain tool. This method takes three arguments: the retriever you have previously created, the name of the tool, and a description of the tool. The description helps the LLM decide when to use this tool and what kind of data it holds.
# Custom Tools
LangChain also empowers developers to define customized tools tailored to their applications or use cases. The simplest way to define a custom tool is by using the @tool decorator with any Python method. Here’s an example:
from langchain.agents import tool
@tool
def get_word_length(word: str) -> int:
"""Returns the length of a word."""
return len(word)
get_word_length.invoke("abc")
In this example, the method name is used as the tool name, and the docstring serves as the tool's description. This setup allows the agent to understand and utilize the tool effectively.
For more complex tools, you can extend the BaseTool class provided by LangChain to create sophisticated custom tools that meet specific needs.
# Toolkit
A toolkit is a collection of tools that an agent can access. It defines the range of actions that the agent can perform and the resources it can utilize. It’s a list of tools that you have defined to be used in the agent just like this:
tool_kit=[retriever_tool,get_word_length]
All the tools in the tool kit act in the same manner no matter how they are defined.
# LLM (Large Language Model)
The LLM is the core of the agent's intelligence, processing natural language inputs, generating responses, and driving the decision-making process. LangChain integrates seamlessly with various state-of-the-art LLMs like GPT-4 (opens new window), BERT (opens new window), and T5 (opens new window), ensuring that agents have access to cutting-edge AI capabilities.
This integration enhances natural language understanding, allows for sophisticated decision-making, and supports customization to specific domains, making LangChain agents versatile and powerful in performing complex tasks.
# Prompt
The prompt is the initial instruction or query that guides the LLM's behavior. Crafting clear and effective prompts is crucial for ensuring that the agent performs tasks accurately and efficiently.
LangChain Hub
LangChain Hub is a central repository for finding, sharing, and managing prompts, chains, agents, and more. It helps developers and teams access high-quality prompts and accelerate their development processes.
Using LangChain Hub
With LangChain Hub (opens new window), you can easily pull a public prompt into your codebase, allowing you to leverage well-crafted prompts tailored to your specific use case and the language model you are using. Here’s how you can import a pre-written prompt:
from langchain import hub
prompt = hub.pull("hwchase17/openai-functions-agent")
The code hub.pull("hwchase17/openai-functions-agent") is used to pull a pre-defined prompt from the LangChain Hub, specifically designed to work with OpenAI functions (opens new window). This particular prompt is part of a collection aimed at enhancing the functionality of agents using OpenAI's powerful language models.
# Agent Executor
The agent executor (opens new window) is a critical element in the LangChain ecosystem. It orchestrates the agent's activities, managing the flow of operations and ensuring that each component functions harmoniously.
From the documentation of LangChain, the workflow of the Agent executor looks roughly like this:
next_action = agent.get_action(...)
while next_action != AgentFinish:
observation = run(next_action)
next_action = agent.get_action(..., next_action, observation)
return next_action
So, basically, it’s a while loop that keeps calling the next action methods on the agent, until the agent has returned its final response. The executor is responsible for:
- Initiating Tasks: It starts the agent's activities based on the given prompt and context.
- Managing Workflow: It coordinates the interaction between tools, the toolkit, and the LLM, ensuring smooth execution of the workflow.
- Handling Errors: It manages any errors or exceptions (opens new window) that occur during the agent's operations, providing robust and reliable performance.
Each of these components plays a vital role in the functionality of an agent. LangChain handles these components with great flexibility, allowing developers to customize and optimize each part according to their needs.

# Create an Agent using MyScaleDB and LangChain
Till now, we've explored the important components needed to build an agent. Now, let's create an agent using MyScaleDB (opens new window) and DuckDuckGo (opens new window). This agent will have two tools:
- Retriever: This tool will fetch information related to MyScaleDB telemetry (opens new window).
- DuckDuckGo Tool: This tool will fetch data from the internet.
# Setting Up the Environment
Before we start building the agent, let's install the necessary tools and technologies. Open your terminal and enter the following command:
pip install langchain langchain_openai duckduckgo-search
This will install all the required packages for building this agent..
# Load the data for the retriever tool
Let’s first load the data for the retriever tool using LangChain's WebBaseLoader:
from langchain_community.document_loaders import WebBaseLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
# Load the data from the internet
loader = WebBaseLoader("https://myscale.com/blog/myscale-telemetry-llm-app-observability/")
docs = loader.load()
# Split the text into smaller chunks
documents = RecursiveCharacterTextSplitter(
chunk_size=1000, chunk_overlap=200
).split_documents(docs)
# Setting MyScaleDB Credentials
Before initializing the retriever, we need to set the credentials for the vector database. We are using MyScale, and you can read more about it in the quickstart guide (opens new window). Set the credentials as follows:
import os
# Credential for the MyScaleDB
os.environ["MYSCALE_HOST"] = "your-hostname-here"
os.environ["MYSCALE_PORT"] = "443"
os.environ["MYSCALE_USERNAME"] = "your-username-here"
os.environ["MYSCALE_PASSWORD"] = "your-password-here"
# Set the OpenAI API key for the OpenAI LLM
os.environ["OPENAI_API_KEY"] = "api-keye-here"
For this project, we will utilize OpenAI embeddings (opens new window) and ChatGPT, which requires setting up the OpenAI API (opens new window) key.
# Initializing the Retriever
Let’s initialize the retriever and put the data into the MyScaleDB retriever (opens new window).
from langchain_community.vectorstores import MyScale
from langchain_openai import OpenAIEmbeddings
vector = MyScale.from_documents(documents, OpenAIEmbeddings())
retriever = vector.as_retriever()
Once the retriever is ready, the next step is to convert the retriever into a langchain tool. For this, we will use create_retriever_tool method:
from langchain.tools.retriever import create_retriever_tool
retriever_tool = create_retriever_tool(
retriever,
"MyScale_telemetry",
"Search for information about MyScale Telemetry. For any questions about Telemetry, you must use this tool!",
)
The defined tool will be used whenever a user query asks about MyScale telemetry. As discussed earlier, the tool's description is very important because it helps the LLM choose the appropriate tool based on the query.
# Defining the Search Tool
Let’s define the second tool for our agent. This is a predefined tool designed to search for current events or fetch the latest information from the internet.
from langchain_community.tools import DuckDuckGoSearchRun
search = DuckDuckGoSearchRun()
# Creating the Toolkit
Our agent will use two tools: the retriever and the web search. Let's create the toolkit:
tools = [search, retriever_tool]
# Initializing the LLM
We'll use OpenAI's GPT-3.5-turbo model for the agent:
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)
# Getting the Prompt
We will use the same pre-defined prompt from the LangChain hub because we are using the OpenAI model for our agent.
from langchain import hub
# Pull the prompt template
prompt = hub.pull("hwchase17/openai-functions-agent")
prompt.messages
# Create the Agent and Agent Executor
LangChain provides several types of agents (opens new window), each designed with unique reasoning capabilities and functionalities. For this project, we'll use the most advanced and robust agent available: the OpenAI Tools agent (opens new window). As highlighted in the official documentation, this agent utilizes the latest models from OpenAI, offering enhanced performance and a broad range of capabilities.
from langchain.agents import create_tool_calling_agent
agent = create_tool_calling_agent(llm, tools, prompt)
Now, let’s pass the agent to the AgentExecutor that will handle all the functionalities of the defined agent.
from langchain.agents import AgentExecutor
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
Setting verbose=True in the AgentExecutor enables detailed logging of the agent's operations. This provides greater transparency and insight into the decision-making process of the agent, which is useful for debugging and understanding how the agent interacts with different tools.
# Adding Memory to the Agent
We add memory to the agent to retain context from previous interactions, which enhances its ability to provide relevant and coherent responses in ongoing conversations. Memory also enables the agent to learn and adapt over time, improving its performance and making interactions more personalized and intelligent.
from langchain.memory import ChatMessageHistory
from langchain_core.runnables.history import RunnableWithMessageHistory
memory = ChatMessageHistory(session_id="test-session")
agent_with_chat_history = RunnableWithMessageHistory(
agent_executor,
lambda session_id: memory,
input_messages_key="input",
history_messages_key="chat_history",
)
Using a session ID helps maintain and organize individual user sessions, ensuring that the agent can accurately track and recall interactions specific to each session.
# Calling the Agent
Finally, we can call the agent to retrieve information. Upon making this query:
# Fetching information about MyScale telemetry
agent_executor.invoke({"input": "What's MyScale telemetry?"}, config={"configurable": {"session_id": "<foo>"}})
The results will be similar to this:
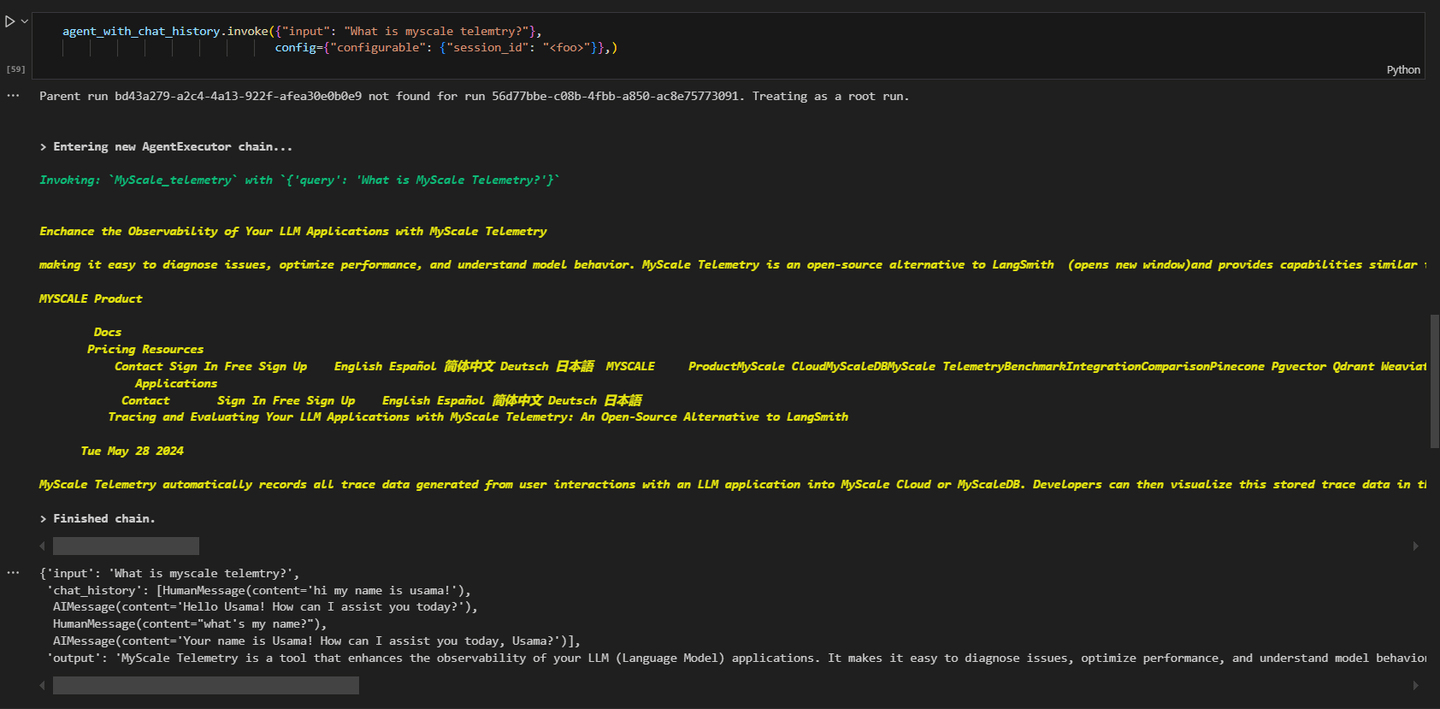
As you can see, the query was related to the MyScale telemetry and the agent is invoking the MyScale_telemetry agent for this.
Let’s make another query and fetch the latest data from the internet.
# Fetching information from the web
agent_executor.invoke({"input": "How's the weather in California?"}, config={"configurable": {"session_id": "<foo>"}})
The results will be similar to this:
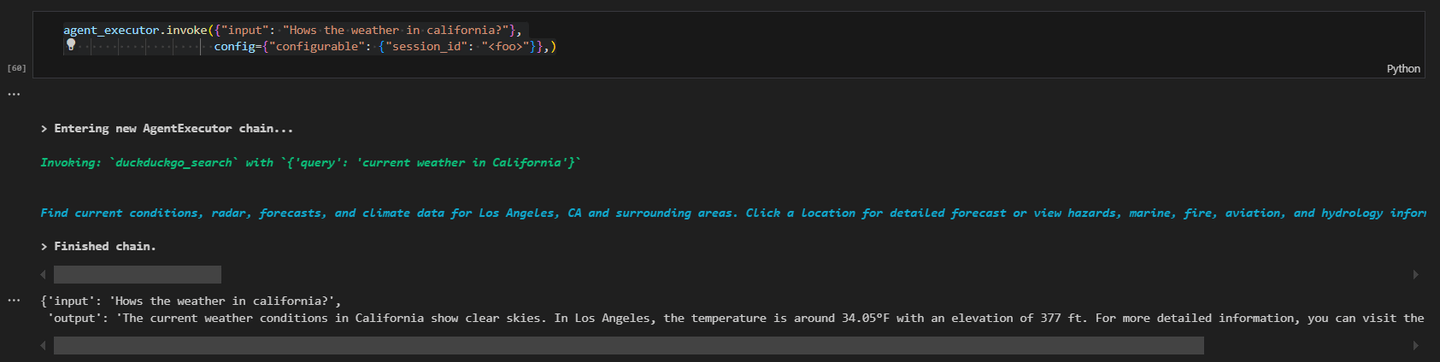
This practical example demonstrates how to create a LangChain agent with MyScaleDB and DuckDuckGo tools. Each component is essential for the agent's functionality, and setting up the environment correctly ensures smooth operation.
# Conclusion
LangChain agents are advanced components that enhance the capabilities of LLMs. They do this by enabling LLMs to make decisions and take actions based on those decisions. Unlike traditional chains that follow a set sequence, agents use LLMs to dynamically determine the sequence of actions. This flexibility allows agents to handle complex and changing tasks more efficiently. LangChain agents are highly modular, making it easy to integrate various tools and custom functions, which lets developers create workflows tailored to specific needs.
MyScaleDB (opens new window) is a top choice among vector databases, known for its superior performance and scalability. Its MSTG (Multi-Stage Tree Graph) algorithm (opens new window) outperforms others by providing faster and more accurate data retrieval, which is vital for AI-driven tasks. MyScaleDB is designed to handle large data loads efficiently, ensuring reliable and high-speed operations. This makes it an essential tool for developers looking to create robust AI applications that require efficient data management and retrieval at scale.



