
Vectors allow us to go beyond the time/resource-consuming learning and use simple searches which are much faster and yet so effective. Vector databases are quite helpful in storing high-dimensional vector data like numeric, text or image data. SQL vector databases like MyScale leave people the trouble of worrying about complex data handling and other backend operations using the power of SQL and some other cool features like MSTG indexing.
Amazon (opens new window)Bedrock (opens new window) is a managed service that allows us to build AI applications with foundation models (for both Text and Image). It provides advantages like AWS’s scalability, allowing us to fine-tune the model privately, etc. We can call these services as seamlessly as normal Python libraries like Scikit-learn or NLTK.
This article demonstrates building a semantic search application for e-books using Amazon Bedrock and MyScale. Traditional e-readers, such as Acrobat Reader, Kindle, Apple Books or some other readers, often limit searches to exact keyword matches. Leveraging Amazon Bedrock's foundation models for embedding generation and MyScale's vector database capabilities, we create a more intelligent search function, moving beyond keyword matching to semantic understanding. By leveraging the strengths of Bedrock’s AI models alongside MyScale’s efficient storage and search capabilities, you can enhance the effectiveness of text searches across a range of applications.
# Installing Libraries
With any Python project, it’s a good practice to make an environment. Here we use Conda to make an environment for the project:
conda create --name AWS python=3.12
After activating it, we will install the respective libraries.
pip install boto3 langchain-aws clickhouse-connect
# Connecting with MyScale
After making the account on MyScale (opens new window), you can run the cluster from the Console (opens new window). You will find the connection string in the cluster details. Simply copy/paste it and connect with the cluster.
import clickhouse_connect
client = clickhouse_connect.get_client(
host='your-host-name-here',
port=443,
username='your-user-name-here',
password='your-password-here')
Note:
For more detailed step-by-step instructions, you can follow the Quickstart guide (opens new window) to get the connection details.
# Testing the Connection
It would be useful to test the connection and the respective library installation by making a small test table.
# Create a table with a 128-dimensional float vector.
client.command("""
CREATE TABLE default.TestTable (
id UInt32,
data Array(Float32),
CONSTRAINT check_length CHECK length(data) = 128,
date Date,
label Enum8('person' = 1, 'building' = 2, 'animal' = 3)
)
ORDER BY id
""")
#['0', 'chi-msc-af209a77-msc-af209a77-0-0', 'OK', '0', '0']
You can check all the tables in the cluster and test the connection by just using “SHOW TABLES” query.
# Get and print the names of all tables in the current database.
res = client.query("SHOW TABLES").named_results()
print([r['name'] for r in res])
# ['TestTable']
# Selecting the Embedding Model
Next, we need to select an appropriate embedding model. Two methods are available to connect to Amazon Bedrock: one is to access the AWS official website to create an IAM user for Bedrock; the other method is to directly utilize MyScale's EmbedText function, which provides a faster way to invoke Amazon Bedrock.
# Connecting with Amazon Bedrock
Amazon Bedrock is one of the several services of AWS. It hosts a number of foundation models for making generative AI applications. RAG is one of the specialized areas of Bedrock. Some of the reasons which make Bedrock a good option include:
- AWS Hosting: AWS hostings are excellent (best in fact) and as a result, we can forget about issues like scalability, security, uptime, etc.
- Simple API: The API, as we will shortly see, is quite easy to use.
- Pay-as-you-go: There is no need to buy big hosting plans. Pay-as-you-go feature allows us to customize our use as per our needs.
# Account Creation
Firstly, you need to make an IAM user (bedrock_test in this case) to use Bedrock.
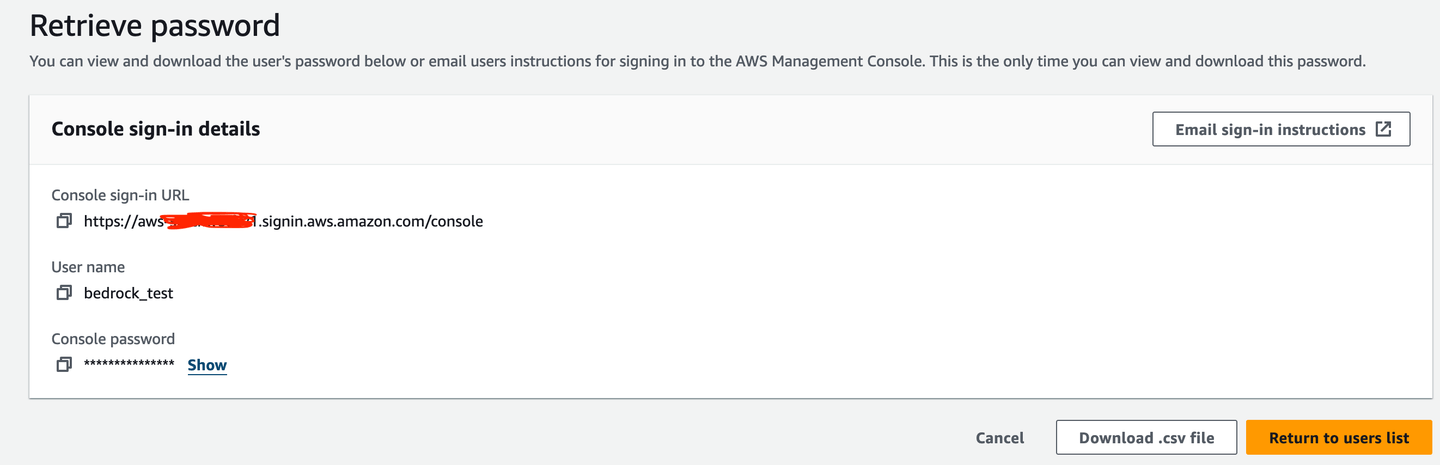
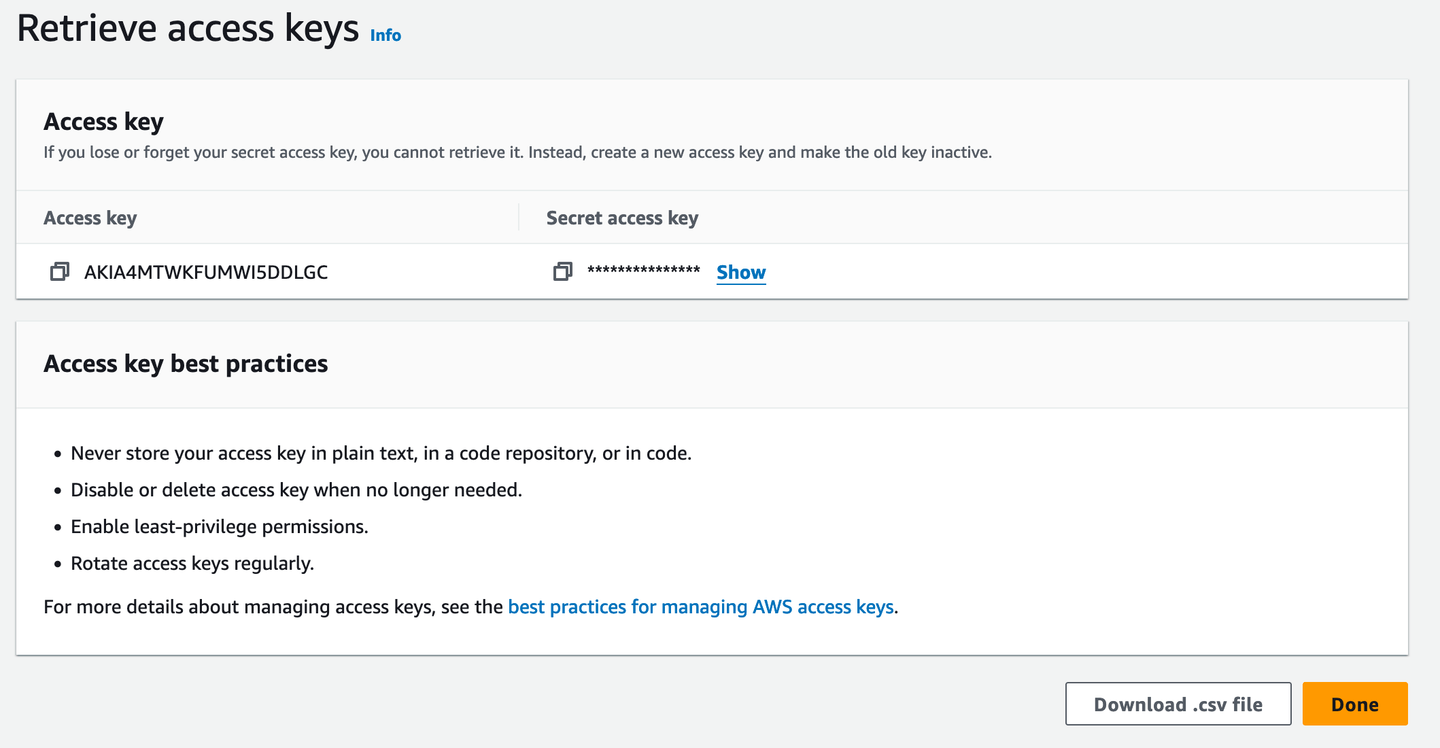
Then, you need an access key for our terminal access.

It would be useful to download it as a .csv file in case you forget the access key. Of course, a password manager is the better option so that you can copy it from there when required.
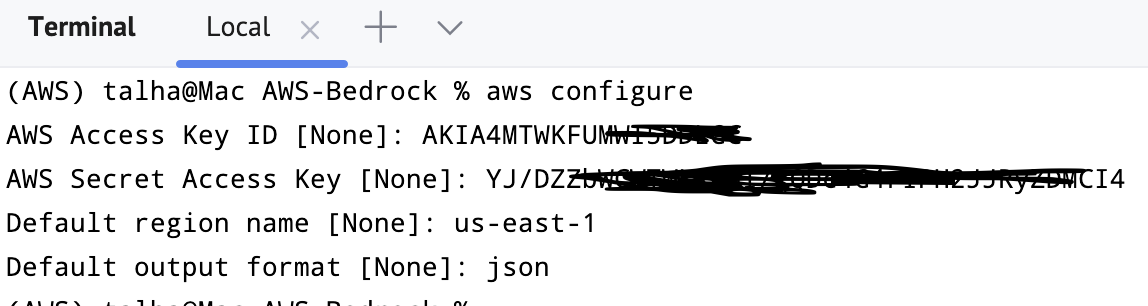
You can verify it by going to the terminal and typing aws configure. It will ask for the credentials, default output format and region.
# Python API
You can import and connect Bedrock with the service. Usually, we prefer to connect to the us-east-1 region.
import boto3
bedrockInterface = boto3.client(service_name="bedrock-runtime", region_name='us-east-1')
It is running successfully, which means the Bedrock client/interface was installed and configured. So far, some preparations are ready:
- Set up and connected MyScale
- Set up and connected Bedrock
# Choosing Models
Before implementing semantic search on the novel using an embedding model, appropriate model selection is required. Unlike the usual data requests which take time and are granted usually immediately, for the model’s access, go to the sidebar’s bottom and you will find the respective option.
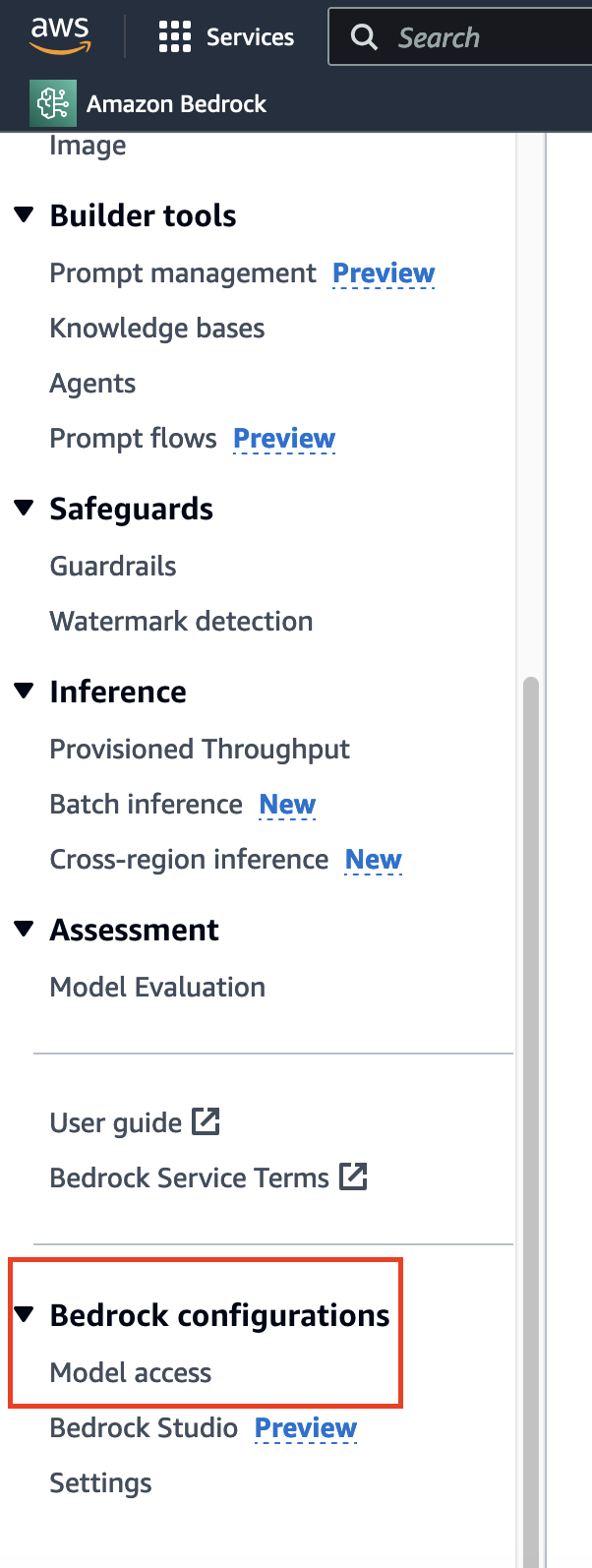
Here, I had already got access, so you would see the “Access Granted” for most of the models. If you are using it for the first time, you can click on the “Modify model access” and enable access to the respective models.

Note:
The availability of some models is dependent on the region you choose (opens new window).
# Titan Embeddings
For this tutorial, we use the Titan Embeddings model (opens new window). Firstly, the invoke_model() method of the client/interface we had just made is applied to use the model. Since we have specified JSON as the modus operandi, so we have to make sure that both inputs and outputs are in this format.
import json
query = "Why number 42 is so significant in the literature?"
query_json = json.dumps({
"inputText": query,
})
Now you can call the invoke_model(). As we can see, the output is a dictionary.
output = bedrockInterface.invoke_model(modelId="amazon.titan-embed-text-v1", body=query_json)
#Output
{'ResponseMetadata': {'RequestId': 'dcbcb135-8b6b-4da4-adbd-523c8c240da6',
'HTTPStatusCode': 200,
'HTTPHeaders': {'date': 'Wed, 18 Sep 2024 03:05:53 GMT',
'content-type': 'application/json',
'content-length': '17180',
'connection': 'keep-alive',
'x-amzn-requestid': 'dcbcb135-8b6b-4da4-adbd-523c8c240da6',
'x-amzn-bedrock-invocation-latency': '68',
'x-amzn-bedrock-input-token-count': '12'},
'RetryAttempts': 0},
'contentType': 'application/json',
'body': <botocore.response.StreamingBody at 0x151b1c880>}
To decode the body, we use the JSON loader again.
response_body = json.loads(output.get('body').read())
#Output
{'embedding': [-0.35351562,
-0.3203125,
-0.083496094,
0.04711914,
0.0034332275,
0.24902344,
-0.13183594,
-4.798174e-06,
-0.28320312,
.
.
.
0.7890625,
...],
'inputTextTokenCount': 12}
It’s good but LangChain provides a much simpler class, BedrockEmbeddings. It will use the bedrockInterface we already declared above.
from langchain_aws import BedrockEmbeddings
embeddingOutput = BedrockEmbeddings(client=bedrockInterface)
BedrockEmbeddings contains a number of methods. One of them is embed_query() which takes a text string and returns the embedding. Since we are using the Titan model, so should expect a 1536 length embedding vector.
x = embeddingGenerator.embed_query("How is it going?")
len(x)
# 1536
# Saving Embeddings in MyScale
Now, we are getting the embeddings from the respective model too, which means we are in a perfect position to utilize the vector database. We will first make the table for storing the text and respective embeddings and use it further for the inference.
client.command("""
CREATE TABLE IF NOT EXISTS BookEmbeddings (
id UInt64,
sentences String,
embeddings Array(Float32),
CONSTRAINT check_data_length CHECK length(embeddings) = 1536
) ENGINE = MergeTree()
ORDER BY id;
""")
# MyScale Embedding Functions
MyScale provides built-in functions for a number of purposes, including the ML models access. One of these functions is EmbedText(), which is so valuable due to a number of reasons:
- Direct interface for calculating text input’s embeddings.
- The ability to call a number of diverse APIs like Bedrock, Hugging Face, Open AI, etc.
EmbedText() (opens new window) takes a number of arguments. If we talk specifically about Bedrock, all we need are:
- Input text: The text whose embedding we want to get.
- Provider: It will be ‘Bedrock’ in our case.
- API URL: Some APIs may use URL, but its not required in our case and will be kept as an empty string.
api_key: The (AWS) secret access key we earlier talked about.access_key_id: Respective key ID.model: Model ID (one on Bedrock).region_name: AWS region name.
For example, we will use this function as:
SELECT EmbedText('Call me Ishmael. Some years ago—never mind how long precisely—having little or no money in my purse, and nothing particular to interest me on shore, I thought I would sail about a little and see the watery part of the world.', 'Bedrock', '', 'xxxxxxxx', '{"model":"amazon.titan-embed-text-v1", "region_name":"us-east-1", "access_key_id":"xxxxxx"}')
Since its a scalar function, so we got this direct output.

Now, everytime we call this function, all the arguments but input text are the same. So, we can customize it as:
CREATE FUNCTION EmbedTest AS (x) -> EmbedText(x, 'Bedrock', '', 'xxxx', '{"model":"amazon.titan-embed-text-v1", "region_name":"us-east-1", "access_key_id":"xxxxx"}')
SELECT EmbedTest('Call me Ishmael. Some years ago—never mind how long precisely—having little or no money in my purse, and nothing particular to interest me on shore, I thought I would sail about a little and see the watery part of the world.')
This customized function can be called easily from anywhere. Having seen this straightforward embedding function (which can be extended with other APIs too), lets go back to our front-end to scrap some text, which we will use in the remainder of the blog.
# Generating Book Embeddings
Now let’s pick a book and generate its embeddings. For example, using Gutenberg (opens new window) to take Tolstoy’s classic (opens new window):
import requests
url = "<https://www.gutenberg.org/files/1399/1399-0.txt>"
response = requests.get(url)
if response.status_code == 200:
bookText = response.content.decode('utf-8-sig')
start = bookText.find("CHAPTER I")
end = bookText.find("End of the Project Gutenberg EBook")
bookText = bookText[start:end]
chapters = re.split(r'(Chapter \\d+)', book_text)
splitChapters = ["".join(x) for x in zip(chapters[1::2], chapters[2::2])]
Now we have Anna Karenina in chapter-by-chapter format. You can pass all of them through the Titan model to get the embeddings.
embeddingsMatrix = [embeddingGenerator.embed_query(chapter) for chapter in splitChapters]
Further, it will be converted into a dataframe and inserted in the table.
import pandas as pd
df = pd.DataFrame({
'Text': splitChapters,
'Embedding': embeddingsMatrix
})
df_records = df.to_records(index=True)
client.insert("BookEmbeddings", df_records.tolist(), column_names=["id", "sentences", "embeddings"])
The data is successfully inserted as we can confirm in the SQL workspace (opens new window) (on the MyScale console).
# Indexing
Indexing is useful for quickly calculating the distance between the embeddings.
client.command("""
ALTER TABLE BookEmbeddings
ADD VECTOR INDEX dist_idx embeddings
TYPE MSTG
""")
It may take a few moments for this index to apply (depending on the data).
# Using MyScale to Search Anna Karenina Novel
After the whole novel is stored in the database and indexing is up, let’s get back to the vector database to run some queries. For example, let’s find the most relevant chapters (in other words, document retrieval).
query = "What happened to Levin's brother?"
queryEmbeddings = embeddingGenerator.embed_query(query)
results = client.command(f"""
SELECT id, sentences, embeddings,
distance(embeddings, {queryEmbeddings}) as dist
FROM BookEmbeddings
ORDER BY dist LIMIT 3
""")
In the following result, you can see that these 3 chapters are most relevant to addressing the query.

query = "When Dolly went to meet Anna at her home?"
query_embeddings = embeddingGenerator.embed_query(query)
results = client.command(f"""
SELECT id, sentences, embeddings,
distance(embeddings, {query_embeddings}) as dist
FROM BookEmbeddings
ORDER BY dist LIMIT 3
""")
Again, the output is remarkable as we can see vector search does pretty well in fetching.

I played around and tried a different measure (Cosine similarity). While the distances were different, I still got the same answers as above. In case you want to try it, please feel free to drop the existing index and add the Cosine similarity index.
client.command("""
ALTER TABLE BookEmbeddings
ADD VECTOR INDEX cosine_idx embeddings
TYPE MSTG
('metric_type=Cosine')
""")

# Conclusion
Using Amazon Bedrock and MyScale for vector search offers a clear improvement over the traditional keyword-based searches found in most e-readers. With semantic search, users can find relevant content even when they don't remember the exact terms, making the reading experience much smoother. While this example focuses on a single novel, this approach can be applied to a wide range of texts, from other books to legal documents or official papers.
The process is also quite accessible. Everything demonstrated here was done using MyScale’s free tier, which provides ample resources for testing and reproducing results. By combining the strengths of Bedrock’s AI models and MyScale’s efficient storage and search capabilities, you can handle text searches more effectively in a variety of applications.



