
The explosive growth of global data, projected to reach 181 zettabytes by 2025 (opens new window), with 80% being unstructured, poses a challenge for traditional databases unable to handle unstructured text data effectively. Full-text search addresses this by enabling intuitive and efficient access to unstructured text data, allowing users to search based on topics or key ideas.
MyScaleDB (opens new window), an open-source fork of ClickHouse optimized for vector search, has enhanced its text search capabilities with the integration of Tantivy (opens new window), a full-text search engine library.
This upgrade significantly benefits those who use ClickHouse for logging, often as a substitute for Elasticsearch or Loki. It also benefits users leveraging MyScaleDB in Retrieval-Augmented Generation (RAG) with large language models (LLMs), combining vector and text search for improved accuracy.
In this post, we'll explore the technical details of the integration process and how it boosts MyScaleDB's performance.
# Limitations of ClickHouse's Native Text Search
ClickHouse provides basic text search functions like hasToken, startsWith, and multiSearchAny, suitable for simple term query scenarios. However, for more complex requirements such as phrase queries, fuzzy text matching, and BM25 relevance ranking, these functions fall short. Hence, in MyScaleDB, we introduced Tantivy as the underlying implementation for full-text indexing, empowering MyScaleDB with full-text search capabilities. Tantivy's full-text index supports fuzzy text queries, BM25 relevance ranking, and accelerates existing functions like hasToken and multiSearchAny term matching.
# Why We Chose Tantivy
Tantivy is an open-source full-text search engine library written in Rust. It's designed for speed and efficiency, particularly in handling large volumes of text data.
# Understanding Tantivy's Core Principles
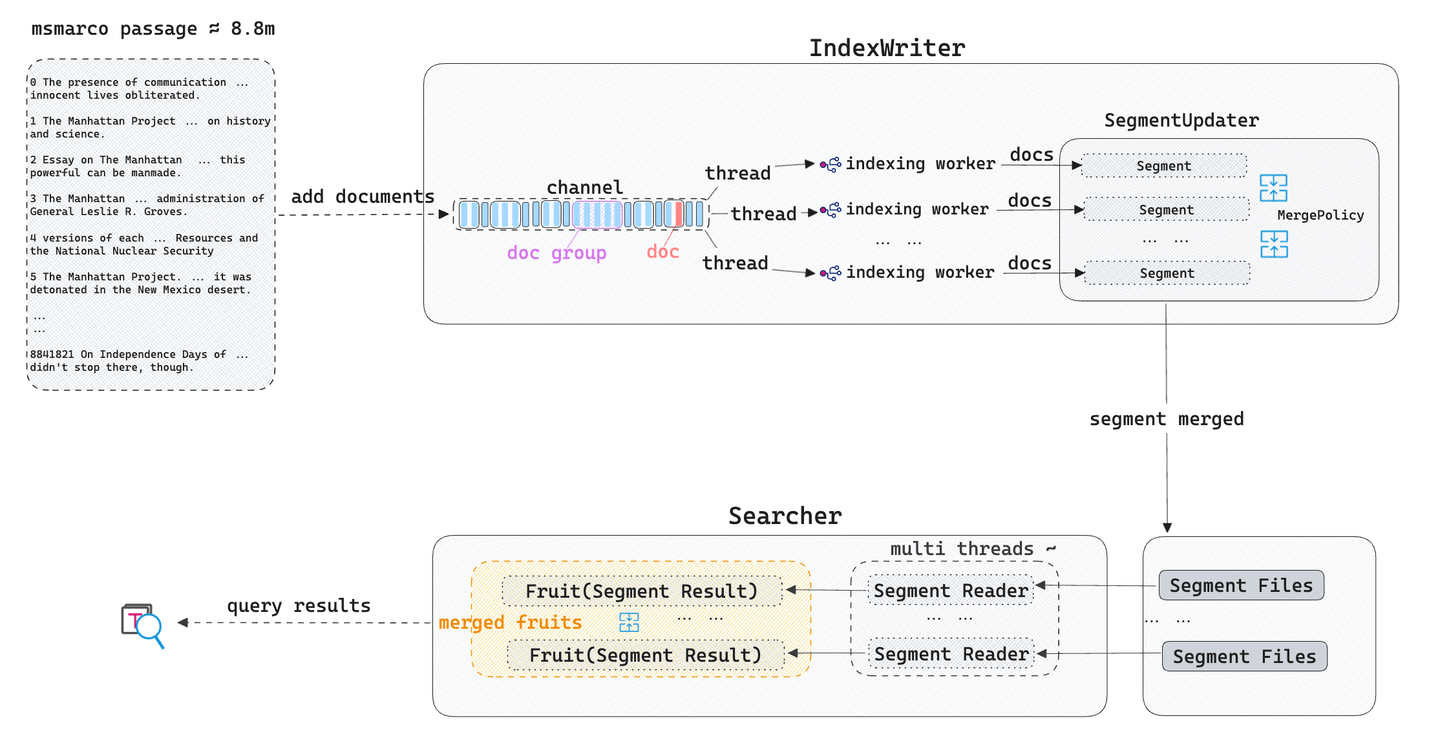
Building the Index: Tantivy tokenizes the input text, splitting it into independent tokens. It then creates an inverted index (posting List) and writes it to index files (segments). Meanwhile, Tantivy's background threads utilize Merge strategies to merge and update these segment index files.
Executing Text Searches: When a user initiates a text search query, Tantivy parses the query statement, extracts tokens, and on each segment, sorts and scores documents based on the query conditions and the BM25 relevance algorithm. Finally, the query results from these segments are merged based on relevance scores and returned to the user.
# Key Features of Tantivy
- BM25 Relevance Scoring: Elasticsearch, Lucene, and Solr all utilize BM25 as the default relevance ranking algorithm. BM25 Score evaluates the accuracy and relevance of text searches, enhancing user search experience.
- Configurable Tokenizers: Supports various language tokenizers, catering to diverse tokenization needs of users.
- Natural Language Queries: Users can flexibly combine text queries using keywords like AND, OR, IN, reducing the complexity of SQL statement writing.
For more functionalities, refer to the Tantivy documentation (opens new window).
# Seamless Integration with MyScaleDB
MyScaleDB, written in C++, is developed on the foundation of ClickHouse and serves as a robust search engine for AI-native applications. To enrich MyScaleDB's full-text search functionality, we needed a library that could be directly embedded into MyScaleDB.
Tantivy is a full-text search library inspired by Apache Lucene. Unlike Elasticsearch, Apache Solr, and other similar engines, Tantivy can be integrated into various databases like MyScaleDB. Tantivy is written in the Rust programming language, which can be integrated with C++ programs easily using Corrosion (opens new window).
# The Integration Process
# Building a C++ Wrapper for Tantivy
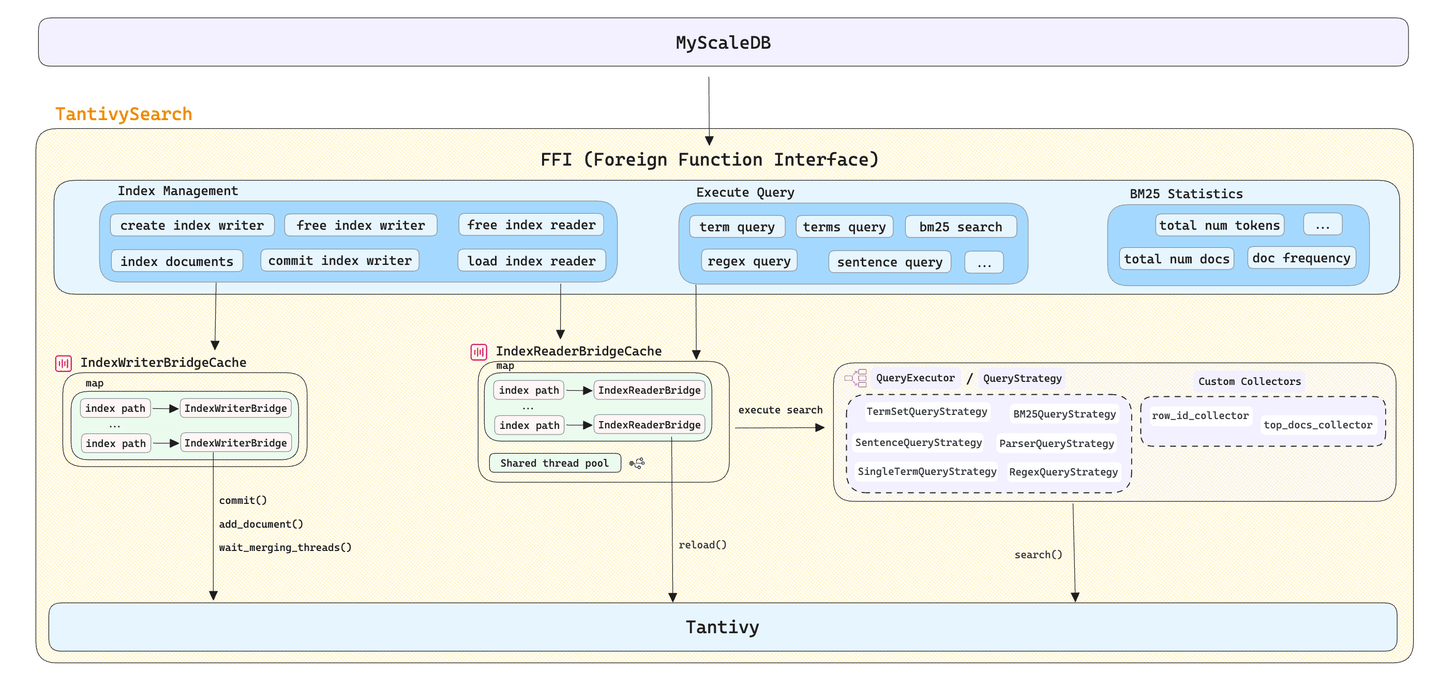
We couldn't directly use the raw Tantivy library in MyScaleDB. To tackle the challenge of cross-language development (C++ & Rust), we developed tantivy-search (opens new window), a C++ wrapper for Tantivy. It provides a set of FFI interfaces for MyScaleDB, enabling direct management of index creation, destruction, loading, and flexible handling of text search requirements in various scenarios.
# Implementing Tantivy as a Skipping Index in ClickHouse
ClickHouse's skipping index (opens new window) is mainly used to accelerate queries with WHERE clauses. We implemented a new skipping index type named FTS (Full-Text Search), with Tantivy as the underlying implementation. So for each data part in ClickHouse with the FTS index, we build a Tantivy index for it. As previously mentioned, Tantivy generates several segment files for each index. To reduce the number of files need to be stored in a data part, MyScaleDB serializes these segment files into two files and stores them in the data part. The skp_idx_[index_name].meta file records the name and offset of each segment file, while the skp_idx_[index_name].data file stores the original data of each segment file.
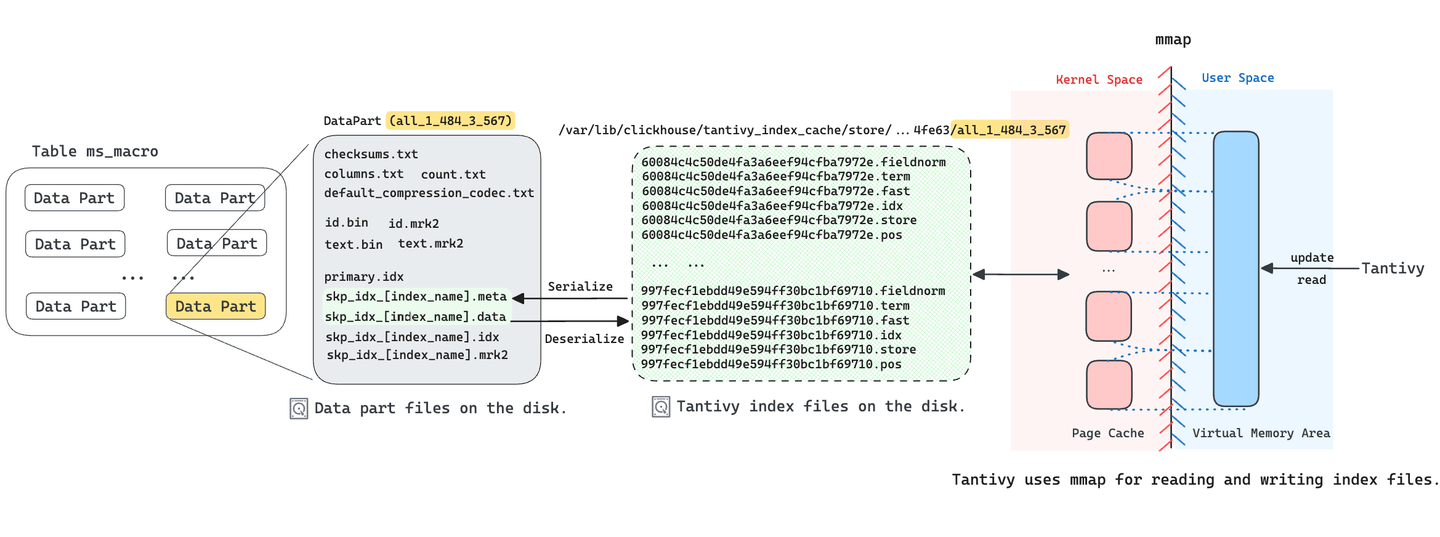
Tantivy utilizes memory mapping (mmap) to access segment files. This approach not only improves concurrent search speed but also enhances index construction efficiency. Since Tantivy cannot map the skp_idx_[index_name].data file to memory directly, when a user initiates a query that needs the FTS index, MyScaleDB will deserialize the index files (.meta and .data) to Tantivy segment files into a temporary directory and load the Tantivy index. These deserialized segment files are loaded via memory mapping by Tantivy for executing various types of text searches. Hence, the initial query request from users may take several seconds to complete.
In the managed MyScaleDB service (opens new window), we store Tantivy's segment index files on NVMe SSDs. This reduces I/O wait time and improves mmap performance in scenarios requiring random access and handling of page fault exceptions.
# Enhancing ClickHouse's Native Text Search Functions
When requests with filtering conditions are initiated on columns containing FTS indexes, MyScaleDB first accesses the FTS index. It retrieves all row IDs of the column that meet the SQL filter conditions and stores these row IDs in an advanced bitmap data structure, known as a roaring bitmap (opens new window). While traversing granules, we determine if a granule's row ID range intersects with the bitmap, indicating whether the granule can be dropped. Ultimately, MyScaleDB only accesses those granules that haven't been dropped, thus achieving query acceleration.
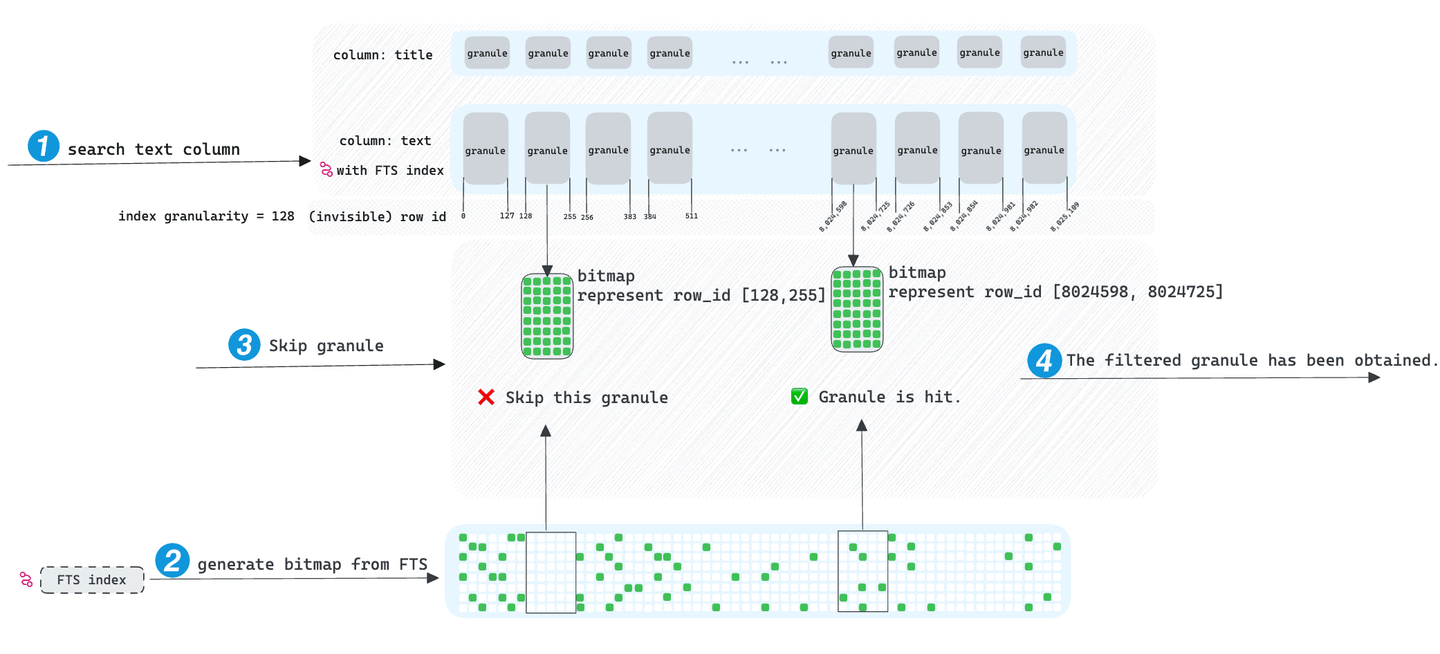
Ideally, the skipping index does accelerate queries, but we found its effect is limited. If the searched term appears in almost all granules, MyScaleDB can only skip a small number of granules, requiring access to a large number of granules for the query, rendering skipping index ineffective in such cases. Excitingly, MyScaleDB introduced the TextSearch function, not only addressing the inefficiency of skipping index but also bringing other practical functionalities.
# Introducing the TextSearch Function
To fully exploit Tantivy's full-text search capabilities, we incorporated the TextSearch function into MyScaleDB. This allows users to execute fuzzy text retrieval requests and obtain a set of documents sorted by BM25 Score relevance. Additionally, users can employ Natural Language Query within the TextSearch function, significantly reducing the complexity of SQL writing.
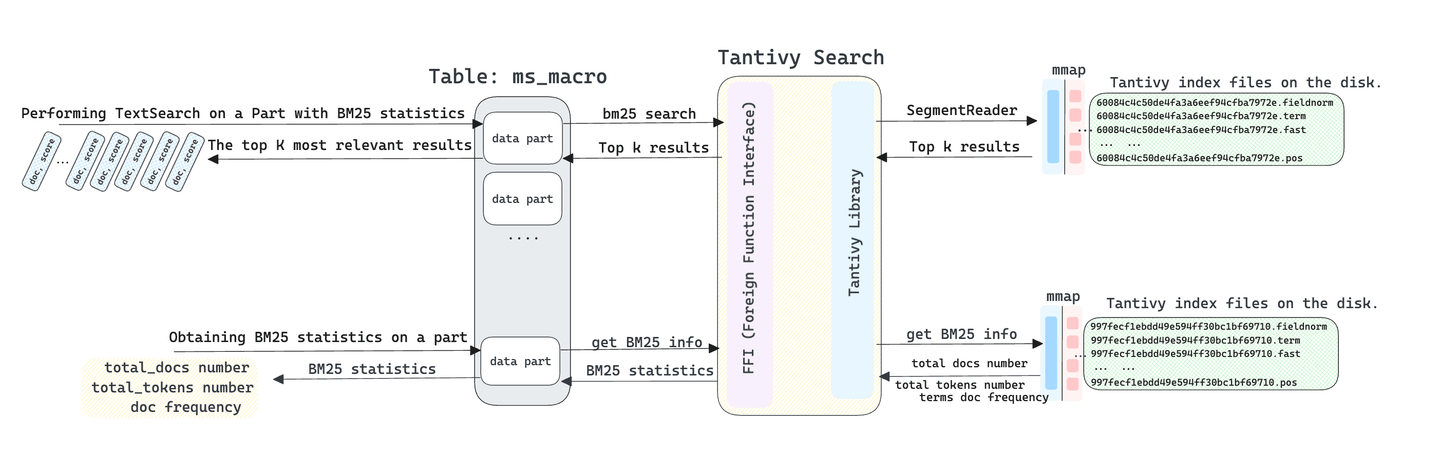
The TextSearch function retrieves the top K most relevant results from the table when searching text. In terms of execution, MyScaleDB concurrently performs TextSearch text retrieval on all data parts. Consequently, each part collects the K most relevant results sorted by BM25 score. MyScaleDB then aggregates these results obtained from data parts based on BM25 scores. Finally, MyScaleDB retains the top K results as per the ORDER BY and LIMIT clauses specified in the user's SQL query. The TextSearch function does not directly read data from within the data part. Instead, it retrieves index search results directly through Tantivy, making it extremely fast.
It's important to note that MyScaleDB utilizes multiple data parts for storing data, with each data part responsible for storing a portion of the entire table's data. We cannot merely average the BM25 scores corresponding to the same answer texts obtained from each part and sort them. This is because each part only considers the "total docs number", "total tokens number", and "doc frequency" within the current part when calculating BM25 scores, without taking into account other BM25 algorithm-related parameters within other parts. Therefore, this would lead to a decrease in the accuracy of the final merged results.
To address this issue, we first calculate the BM25 statistics within each part before initiating the TextSearch query. Then, we consolidate them into logically corresponding BM25 statistics for the entire table. Additionally, we have modified the Tantivy library to support the use of shared BM25 information. This ensures the correctness of the TextSearch search results across multiple Parts.
Below is a simple example of using the TextSearch function to perform a basic text search on the ms_macro dataset. For more information on how to use the TextSearch function, refer to our TextSearch document (opens new window).
SELECT
id,
text,
TextSearch(text, 'who is Obama') AS score
FROM ms_macro
ORDER BY score DESC
LIMIT 5
Output:
| id | text | score |
|---|---|---|
| 2717481 | Sasha Obama Biography. Name at birth: Natasha Obama. Sasha Obama is the younger daughter of former U.S. president Barack Obama. Her formal name is Natasha, but she is most often called by her nickname, Sasha. Sasha Obama was born in 2001 to Barack Obama and his wife, Michelle Obama, who were married in 1992. Sasha Obama has one older sister, Malia, who was born in 1998. | 15.448088 |
| 5016433 | Sasha Obama Biography. Sasha Obama is the younger daughter of former U.S. president Barack Obama. Her formal name is Natasha, but she is most often called by her nickname, Sasha. Sasha Obama was born in 2001 to Barack Obama and his wife, Michelle Obama, who were married in 1992. Sasha Obama has one older sister, Malia, who was born in 1998. | 15.407547 |
| 564474 | Michelle Obama net worth: $11.8 Million. Michelle Obama Net Worth: Michelle Obama is an American lawyer, writer and First Lady of the United States who has a net worth of $11.8 million.Michelle Obama was born January 17, 1964 in Chicago, Illinois.ichelle Obama net worth: $11.8 Million. Michelle Obama Net Worth: Michelle Obama is an American lawyer, writer and First Lady of the United States who has a net worth of $11.8 million. | 14.88242 |
| 5016431 | Name at birth: Natasha Obama. Sasha Obama is the younger daughter of former U.S. president Barack Obama. Her formal name is Natasha, but she is most often called by her nickname, Sasha. Sasha Obama was born in 2001 to Barack Obama and his wife, Michelle Obama, who were married in 1992. | 14.63069 |
| 1939756 | Michelle Obama Net Worth: Michelle Obama is an American lawyer, writer and First Lady of the United States who has a net worth of Michelle Obama Net Worth: Michelle Obama is an American lawyer, writer and First Lady of the United States who has a net worth of $40 million. Michelle Obama was born January 17, 1964 in Chicago, Illinois. She is best known for being the wife of the 44th President of the United States, Barack Obama. She attended Princeton University, graduating cum laude in 1985, and went on to earn a law degree from Harvard Law School in 1988. | 14.230849 |

# Performance Evaluation
We compared the search performance of MyScaleDB under different indexes using clickhouse-benchmark (opens new window), including MyScaleDB's implemented FTS index, ClickHouse's built-in Inverted Index, and the scenario without any index.
# Benchmark Setup
# Dataset Details
To test the TextSearch performance, we utilized the ms_macro dataset (opens new window) provided by Microsoft. The ms_macro dataset consists of 8,841,823 text records, which we converted to the parquet format for easy import into MyScaleDB. Additionally, we created a set of SQL files for testing search performance based on different word frequencies. Readers can access the dataset used in this test via S3:
- ms_macro_text.parquet (opens new window): 1.6GB
- ms_macro_query_files.tar.gz (opens new window): 5.8MB
The ms_macro_query_files.tar.gz file encompasses all the SQL files used in this test. For example, the name of each SQL file indicates the frequency of the searched term in ms_macro dataset and the number of queries included in the SQL file. For example, the ms_macro_count_hastoken_100_100k.sql file contains 100k queries and the word in each query appears 100 times in the dataset.
The following are examples of hasToken and TextSearch queries:
SELECT count(*) FROM ms_macro WHERE hasToken(text, 'Crimp');
SELECT count(*) FROM (
SELECT TextSearch(text, 'Crimp') AS score
FROM ms_macro ORDER BY score DESC LIMIT 10000000
) as subquery;
# Testing Environment
Despite our testing environment having 64GB of memory, the memory consumption of MyScaleDB during testing remains around 2.5GB.
| Item | Value |
|---|---|
| System Version | Ubuntu 22.04.3 LTS |
| CPU | 16 cores (AMD Ryzen 9 6900HX) |
| Memory Speed | 64GB |
| Disk | 512GB NVMe SSD |
| MyScaleDB | v1.5 |
# Data Import Procedure
Create a table for the ms_macro dataset:
CREATE TABLE default.ms_macro
(
`id` UInt64,
`text` String
)
ENGINE = MergeTree
ORDER BY id
SETTINGS index_granularity = 128;
Directly import data from S3 into MyScaleDB:
INSERT INTO default.ms_macro
SELECT * FROM
s3('https://myscale-datasets.s3.ap-southeast-1.amazonaws.com/ms_macro_text.parquet','Parquet');
Merge the data parts of ms_macro into one to enhance search speed. Note that this operation is optional.
OPTIMIZE TABLE default.ms_macro final;
SELECT count(*) FROM system.parts WHERE table = 'ms_macro';
Output:
| count() |
|---|
| 1 |
Verify if ms_macro contains 8,841,823 records:
SELECT count(*) FROM default.ms_macro;
Output:
| count() |
|---|
| 8841823 |
# Index Creation
We will evaluate the performance of three types of indexes: FTS, Inverted, and None (a scenario without any index).
- Create FTS Index
-- Ensure that when creating the FTS index, no other index exists on the text column of ms_macro.
ALTER TABLE default.ms_macro DROP INDEX IF EXISTS fts_idx;
ALTER TABLE default.ms_macro ADD INDEX fts_idx text TYPE fts;
ALTER TABLE default.ms_macro MATERIALIZE INDEX fts_idx;
- Create Inverted Index
-- Ensure that when creating the Inverted index, no other index exists on the text column of ms_macro.
ALTER TABLE default.ms_macro DROP INDEX IF EXISTS inverted_idx;
ALTER TABLE default.ms_macro ADD INDEX inverted_idx text TYPE inverted;
ALTER TABLE default.ms_macro MATERIALIZE INDEX inverted_idx;
- None Index: Ensure that the text column of the ms_macro table does not contain any index.
# Running the Benchmark
Use clickhouse-benchmark to perform stress testing. For more usage instructions, please refer to the ClickHouse documentation (opens new window).
clickhouse-benchmark -c 8 --timelimit=60 --randomize --log_queries=0 --delay=0 < ms_macro_count_hastoken_100_100k.sql -h 127.0.0.1 --port 9000
# Evaluation Results
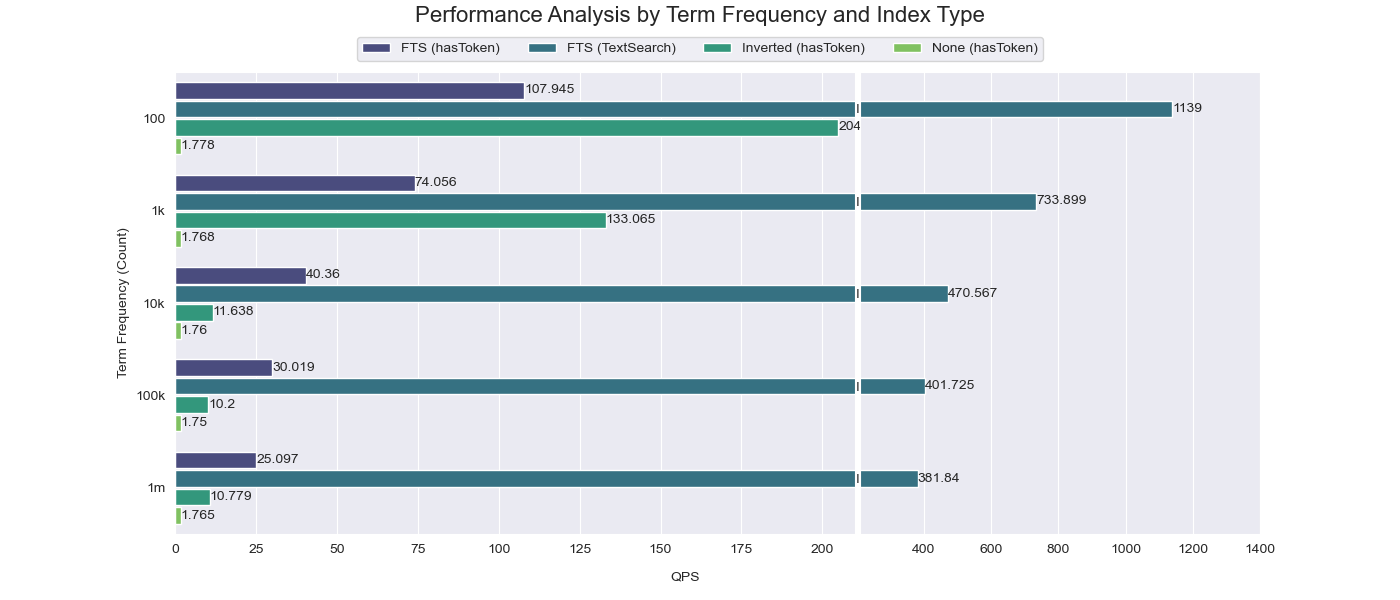
From the comparison results, it's clear that when the frequency of the searched word is high (100K~1M), the acceleration effect of the skipping index is quite limited (only a tenfold improvement compared to performance without establishing any index). However, when the frequency of the searched word is low (100~1K), the skipping index can achieve a significant acceleration effect (up to a hundredfold improvement compared to performance without establishing any index).
The TextSearch function, on the other hand, consistently outperforms both the skipping index and the inverted index across all scenarios. This is because TextSearch directly leverages Tantivy's full-text search capabilities, bypassing the need to scan through granules and instead retrieving results directly from the index. This results in a much faster and more efficient search process.
# Conclusion
Integrating Tantivy into MyScaleDB has significantly enhanced its text search capabilities, making it a powerful tool for text data analysis and Retrieval-Augmented Generation (RAG) with large language models (LLMs). By addressing the limitations of ClickHouse's native text search functions and introducing advanced features like BM25 relevance scoring, configurable tokenizers, and natural language queries, MyScaleDB now offers a robust and efficient solution for complex text search requirements.
The implementation of a C++ wrapper for Tantivy, the creation of a new skipping index, and the introduction of the TextSearch function have all contributed to this improvement. These enhancements not only boost MyScaleDB's performance but also expand its use cases, making it a top choice for efficient and accurate text search in various applications.
For more information on how to use the TextSearch function and other features, refer to our documentation on text search (opens new window) and hybrid search (opens new window).
We hope this post has provided valuable insights into the integration process and the benefits it brings to MyScaleDB. Stay tuned for more updates and improvements as we continue to enhance MyScaleDB's capabilities.
This article is originally published on The New Stack. (opens new window)



