
The development of scalable and optimized AI applications using Large Language Models (LLMs) is still in its growing stages. Building applications based on LLMs is complex and time-consuming due to the extensive manual work involved, such as prompt writing. Prompt writing is the most important part of any LLM application as it helps us to extract the best possible results from the model. However, crafting an optimized prompt requires developers to rely heavily on hit-and-trial methods, wasting significant time until the desired result is achieved.
The conventional method of manually crafting prompts is time-consuming and error-prone. Developers often spend significant time tweaking prompts to achieve the desired output, facing issues like:
- Fragility: Prompts can break or perform inconsistently with slight changes.
- Manual Adjustments: Extensive manual effort is required to refine prompts.
- Inconsistent Handling: Different prompts for similar tasks lead to inconsistent results.
# What is DSPy?
DSPy (Declarative Self-improving Language Programs), pronounced as “dee-s-pie,” is a framework designed by Omer Khattab and his team at Stanford NL. It aims to resolve the consistency and reliability issues of prompt writing by prioritizing programming over manual prompt writing. It provides a more declarative, systematic, and programmatic approach to building data pipelines allowing developers to create high-level workflows without focusing on low-level details.
DSPy logo
It lets you define what to achieve rather than how to achieve it. So, in order to accomplish that, DSPy has made advancements:
- Abstraction Over Prompts: DSPy has introduced the concept of signatures. Signatures aim to replace manual prompt wording with a template-like structure. In this structure, we only need to define the inputs and outputs for any given task. This will make our pipelines more resilient and flexible to changes in the model or data.
- Modular Building Blocks: DSPy provides modules that encapsulate common prompting techniques (like Chain of Thought or ReAct). This eliminates the need for manually constructing complex prompts for these techniques.
- Automated Optimization: DSPy supports built-in optimizers, also referred to as "teleprompters” that automatically select the best prompts for your specific task and model. This functionality eliminates the need for manual prompt tuning, making the process simpler and more efficient.
- Compiler-Driven Adaptation: The DSPy compiler optimizes the entire pipeline, adjusting prompts or fine-tuning models based on your data and validation logic, ensuring the pipeline remains effective even as components change.
# Building Blocks of a DSPy Program
Let's explore the essential components that form the foundation of a DSPy program and understand how they interact to create powerful and efficient NLP pipelines.
# Signatures
Signatures serve as the blueprint for defining what you want your LLM to do. Instead of writing the exact prompt, you describe the task in terms of its inputs and outputs.
For example, a signature for summarizing text might look like this: text -> summary. This tells DSPy that you want to input some text and receive a concise summary as output. More complex tasks might involve multiple inputs, like a question-answering signature: context, question -> answer. Signatures are flexible and can be customized with additional information, such as descriptions of the input and output fields.
class GenerateAnswer(dspy.Signature):
"""Answer questions with short factoid answers."""
context = dspy.InputField(desc="may contain relevant facts")
question = dspy.InputField()
answer = dspy.OutputField(desc="often between 1 and 5 words")
# Modules: Building Blocks for LLM Behavior
Modules are pre-built components that encapsulate specific LLM behaviors or techniques. They are the building blocks you use to assemble your LLM application. For instance, the ChainOfThought module encourages the LLM to think step-by-step, making it better at complex reasoning tasks. The ReAct module allows your LLM to interact with external tools like calculators or databases. You can chain multiple modules together to create sophisticated pipelines.
# Method 1: Pass the Class to the ChainOfThought module
chain_of_thought = ChainOfThought(TranslateText)
Each module takes a signature and, using the defined method like ChainOfThought constructs the necessary prompt based on the defined inputs and outputs. This method ensures that the prompts are systematically generated, maintaining consistency and reducing the need for manual prompt writing.
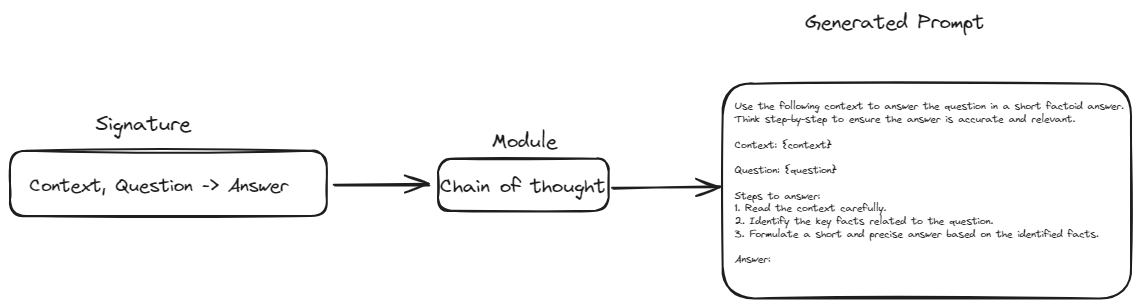
In this way, the module takes the signature, applies its specific behavior or technique, and generates a prompt that aligns with the task's requirements. This integration of signatures and modules allows for building complex and flexible LLM applications with minimal manual intervention.
# Teleprompters (Optimizers): The Prompt Whisperers
Teleprompters are like coaches for your LLM. They use advanced techniques to find the best prompts for your specific task and model. They do this by automatically trying out different variations of prompts and evaluating their performance based on a metric you define. For example, a teleprompter might use a metric like accuracy for question-answering tasks or ROUGE score for text summarization.
from dspy.teleprompt import BootstrapFewShot
# Simple teleprompter example
teleprompter = BootstrapFewShot(metric=dspy.evaluate.answer_exact_match)
# DSPy Compiler: The Master Orchestrator
The DSPy compiler is the brains behind the operation. It takes your entire program – including your signatures, modules, training data, and validation logic – and optimizes it for peak performance. The compiler's ability to automatically handle changes in your application makes DSPy incredibly robust and adaptable.
from dspy.teleprompt import BootstrapFewShot
# Small training set with question and answer pairs
trainset = [dspy.Example(question="What is Albert Einstein best known for developing?",
answer="The theory of relativity").with_inputs('question'),
dspy.Example(question="What famous equation did Albert Einstein's theory of relativity produce?",
answer="E = mc²").with_inputs('question'),
dspy.Example(question="Which prestigious award did Albert Einstein receive in 1921?",
answer="The Nobel Prize in Physics").with_inputs('question'),
dspy.Example(question="In which year did Albert Einstein move to the United States?",
answer="1933").with_inputs('question'),
dspy.Example(question="What significant scientific work did Einstein publish in 1905, sometimes referred to as his annus mirabilis (miracle year)?",
answer="Four groundbreaking papers including theories on the photoelectric effect, Brownian motion, special theory of relativity, and mass-energy equivalence").with_inputs('question'),]
# Set up a basic teleprompter, which will compile our RAG program.
teleprompter = BootstrapFewShot(metric=dspy.evaluate.answer_exact_match)
compiled_rag = teleprompter.compile(RAG(), trainset=trainset)
The DSPy compiler takes the basic prompt, training examples, and DSPy program to generate an optimized and best-performing prompt. This process involves simulating various versions of the program on the inputs and bootstrapping example traces of each module to optimize the pipeline for your task.
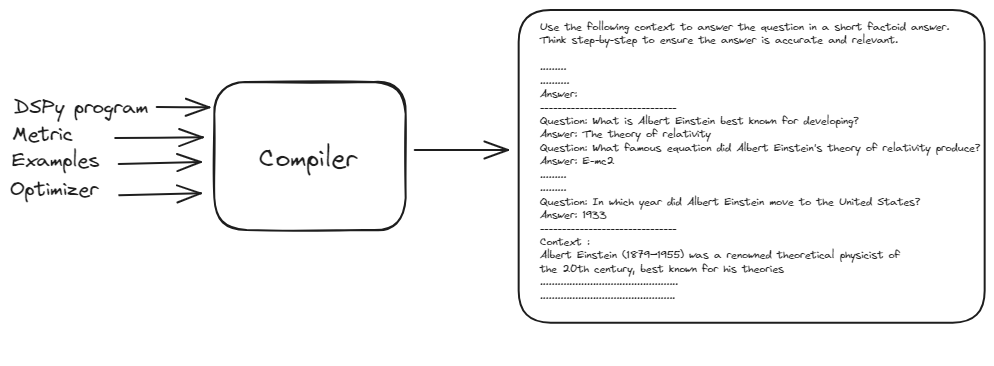
This automated optimization process eliminates the need for manual prompt tuning, making DSPy robust and adaptable to changes, ultimately delivering a highly effective and efficient NLP pipeline
# Practical Example: Build a RAG Model Using DSPy and MyScaleDB
Now that we have covered the basics of DSPy, let's create a practical application. We will build a question-answering RAG pipeline and use MyScaleDB as a vector database.
# 1. Loading Documents from Wikipedia
We start by loading documents related to "Albert Einstein" from Wikipedia. This is done using the WikipediaLoader from the langchain_community.document_loaders module.
from langchain_community.document_loaders.wikipedia import WikipediaLoader
loader = WikipediaLoader(query="Albert Einstein")
# Load the documents
docs = loader.load()
# 2. Transforming Documents to Plain Text
Next, we transform the loaded documents into plain text using the Html2TextTransformer.
from langchain_community.document_transformers import Html2TextTransformer
html2text = Html2TextTransformer()
docs_transformed = html2text.transform_documents(docs)
# Get the cleaned text
cleaned_text = docs_transformed[0].page_content
text = ' '.join([page.page_content.replace('\\t', ' ') for page in docs_transformed])
# 3. Splitting Text into Chunks
The text is split into manageable chunks using the CharacterTextSplitter. This helps in handling large documents and ensures the model processes them efficiently.
import os
from langchain_text_splitters import CharacterTextSplitter
# Set the API key as an environment variable
os.environ["OPENAI_API_KEY"] = "your_openai_api_key"
# Split the text into chunks
text = ' '.join([page.page_content.replace('\\\\t', ' ') for page in docs])
text_splitter = CharacterTextSplitter(
separator="\\n",
chunk_size=300,
chunk_overlap=50,
length_function=len,
is_separator_regex=False,
)
texts = text_splitter.create_documents([text])
splits = [item.page_content for item in texts]
# 8. Defining the Embeddings Model
We use the transformers library to define an embedding model. We will use the all-MiniLM-L6-v2 model to transform the text into vector embeddings.
import torch
from transformers import AutoTokenizer, AutoModel
# Initialize the tokenizer and model for embeddings
tokenizer = AutoTokenizer.from_pretrained("sentence-transformers/all-MiniLM-L6-v2")
model = AutoModel.from_pretrained("sentence-transformers/all-MiniLM-L6-v2")
def get_embeddings(texts: list) -> list:
inputs = tokenizer(texts, padding=True, truncation=True, return_tensors="pt", max_length=512)
with torch.no_grad():
outputs = model(**inputs)
embeddings = outputs.last_hidden_state.mean(dim=1)
return embeddings.numpy().tolist()
# 7. Getting the Embeddings
We generate embeddings for the text chunks using the above embedding model.
import pandas as pd
all_embeddings = []
for i in range(0, len(splits), 25):
batch = splits[i:i+25]
embeddings_batch = get_embeddings(batch)
all_embeddings.extend(embeddings_batch)
# Create a DataFrame with the text chunks and their embeddings
df = pd.DataFrame({
'page_content': splits,
'embeddings': all_embeddings
})
# 8. Connecting to the Vector Database
We will use MyScaleDB (opens new window) as a vector database to develop this sample application. You can create a free account on MyScaleDB by visiting the MyScale Sign (opens new window)Up page (opens new window). After that, you can follow the Quickstart tutorial (opens new window) to start a new cluster and get the connection details.
import clickhouse_connect
client = clickhouse_connect.get_client(
host='your-cloud-host',
port=443,
username='your-user-name',
password='your-password'
)
Copy and paste the connection details into your Python notebook and Run the code block. It will connect with your MyScaleDB cluster on the cloud.
# 9. Creating a Table and Pushing Data
Let's break down the process of creating a table on the MyScaleDB cluster. First, we'll create a table named RAG. This table will have three columns: id, page_content, and embeddings. The id column will hold the unique id of each row, the page_content column will store the textual content, and the embeddings column will save the embeddings of corresponding page content.
# Create the table
client.command("""
CREATE TABLE IF NOT EXISTS default.RAG (
id Int64,
page_content String,
embeddings Array(Float32),
CONSTRAINT check_data_length CHECK length(embeddings) = 384
) ENGINE = MergeTree()
ORDER BY id
""")
# Insert data into the table
batch_size = 100
num_batches = (len(df) + batch_size - 1) // batch_size
for i in range(num_batches):
batch_data = df[i * batch_size: (i + 1) * batch_size]
client.insert('default.RAG', batch_data.values.tolist(), column_names=batch_data.columns.tolist())
print(f"Batch {i+1}/{num_batches} inserted.")
After creating the table, we save the data to the newly created RAG table in the form of batches.
# 10. Configuring DSPy with MyScaleDB
We connect DSPy and MyScaleDB, and configure DSPy to use our language and retrieval models by default.
import dspy
import openai
from dspy.retrieve.MyScaleRM import MyScaleRM
# Set OpenAI API key
openai.api_key = "your_openai_api_key"
# Configure LLM
lm = dspy.OpenAI(model="gpt-3.5-turbo")
# Configure retrieval model
rm = MyScaleRM(client=client,
table="RAG",
local_embed_model="sentence-transformers/all-MiniLM-L6-v2",
vector_column="embeddings",
metadata_columns=["page_content"],
k=6)
# Configure DSPy to use the following language model and retrieval model by default
dspy.settings.configure(lm=lm, rm=rm)
Note: The embedding model we use here should be the same one defined above.
# 11. Defining the Signature
We define the GenerateAnswer signature to specify the inputs and outputs for our question-answering task.
class GenerateAnswer(dspy.Signature):
"""Answer questions with short factoid answers."""
context = dspy.InputField(desc="may contain relevant facts")
question = dspy.InputField()
answer = dspy.OutputField(desc="often between 1 and 5 words")
# 12. Defining the RAG Module
The RAG module integrates retrieval and generation steps. It retrieves relevant passages and generates answers based on the context.
class RAG(dspy.Module):
def __init__(self, num_passages=3):
super().__init__()
self.retrieve = dspy.Retrieve(k=num_passages)
self.generate_answer = dspy.ChainOfThought(GenerateAnswer)
def forward(self, question):
context = self.retrieve(question).passages
prediction = self.generate_answer(context=context, question=question)
return dspy.Prediction(context=context, answer=prediction.answer)
The forward method accepts the question as input and utilizes the retriever to find relevant chunks from the integrated database. These retrieved chunks are then passed to the ChainOfThought module to generate a foundational prompt.
# 13. Setting Up Teleprompters
Next, we will use the BootstrapFewShot teleprompter/optimizer to compile and optimize our basic prompt.
from dspy.teleprompt import BootstrapFewShot
# Small training set with question and answer pairs
trainset = [dspy.Example(question="What is Albert Einstein best known for developing?",
answer="The theory of relativity").with_inputs('question'),
dspy.Example(question="What famous equation did Albert Einstein's theory of relativity produce?",
answer="E = mc²").with_inputs('question'),
dspy.Example(question="Which prestigious award did Albert Einstein receive in 1921?",
answer="The Nobel Prize in Physics").with_inputs('question'),
dspy.Example(question="In which year did Albert Einstein move to the United States?",
answer="1933").with_inputs('question'),
dspy.Example(question="What significant scientific work did Einstein publish in 1905, sometimes referred to as his annus mirabilis (miracle year)?",
answer="Four groundbreaking papers including theories on the photoelectric effect, Brownian motion, special theory of relativity, and mass-energy equivalence").with_inputs('question'),]
# Set up a basic teleprompter, which will compile our RAG program.
teleprompter = BootstrapFewShot(metric=dspy.evaluate.answer_exact_match)
# Compile the RAG pipeline with the teleprompter
compiled_rag = teleprompter.compile(RAG(), trainset=trainset)
This code tasks the RAG class defined above and uses the examples along with the optimizer to generate the best possible prompt for our LLM.
# 14. Running the Pipeline
Finally, we run our compiled RAG pipeline to answer questions based on the context stored in MyScaleDB.
# Retrieve relevant documents
retrieve_relevant_docs = dspy.Retrieve(k=5)
context = retrieve_relevant_docs("Who is Albert Einstein?").passages
# Make the query
pred = compiled_rag(question="Who was Albert Einstein?")
This will generate an output like this:
['Albert Einstein (1879–1955) was a renowned theoretical physicist of the 20th century,
best known for his theories of special relativity ........
.......
originality have made the word "Einstein" synonymous with "genius".']

# Conclusion
DSPy framework has revolutionized our interaction with LLMs by replacing hard-coded prompts with a programmable interface, significantly streamlining the development process. This transition from manual prompt writing to a more structured, programming-oriented methodology has enhanced AI applications' efficiency, consistency, and scalability. By abstracting the complexities of prompt engineering, DSPy allows developers to focus on defining high-level logic and workflows, thereby accelerating the deployment of sophisticated AI-driven solutions.
MyScaleDB, a vector database specifically developed for AI applications, plays a crucial role in enhancing the performance of such systems. Its advanced, proprietary algorithms boost the speed and accuracy of AI applications. Additionally, MyScaleDB is cost-effective, offering new users free storage for up to 5 million vectors. This makes it an attractive option for startups and researchers looking to utilize robust database solutions without the initial investment.



