
Vector databases (opens new window) and vector searches (opens new window) are rapidly gaining popularity due to their impressive speed and scalability. Unlike traditional machine learning models, these databases leverage efficient similarity measures like Euclidean distance (opens new window), Cosine similarity (opens new window), etc. to deliver fast search results without requiring extensive training. This efficiency, coupled with their cost-effectiveness compared to ML-based alternatives, makes them an attractive solution for various applications.
Given the burgeoning landscape of vector databases, choosing the right one for your specific needs can be challenging. Factors like throughput, cost, and functionality play a crucial role in determining the ideal fit.
This article, the third in our series, delves into a detailed comparison of two prominent contenders: MyScaleDB (opens new window) and Qdrant (opens new window). Both databases offer unique advantages, making a comprehensive analysis essential for informed decision-making.
Note: If you are new to vector databases, we recommend starting with the first article (opens new window) in this series for a foundational understanding of this powerful technology.
# Introduction of MyScaleDB and Qdrant
# MyScaleDB
MyScaleDB stands out as a cloud-native database optimized for AI applications and solutions. Built on the robust foundation of the open-source and highly scalable ClickHouse database (opens new window), MyScaleDB offers several compelling advantages:
- Unified Platform for AI: MyScaleDB streamlines AI workflows by seamlessly managing and processing both structured and vectorized data within a single, unified platform. This eliminates the need for complex data pipelines and simplifies development processes.
- Uncompromising Performance: Leveraging a cutting-edge OLAP database architecture, MyScaleDB delivers exceptional performance for operations on vectorized data. This architecture enables lightning-fast query execution, making it ideal for demanding AI workloads.
- SQL-Powered Simplicity: MyScaleDB embraces the universality of SQL, allowing developers to interact with the database using a familiar and widely adopted language. This eliminates the need to learn specialized query languages, accelerating development cycles and boosting productivity.
- MSTG Indexing for Enhanced Search: MyScaleDB utilizes the Multi-Scale Tree Graph Algorithm (MSTG) (opens new window) algorithm, an advanced indexing algorithm (opens new window) designed for high data density and optimized search performance. MSTG excels in both basic and filtered vector searches (opens new window), ensuring fast and accurate retrieval of relevant information.
# Qdrant
Qdrant is another contemporary vector database. It’s also open-source and available both in Docker and cloud. Some of the features of Qdrant are:
- Advanced Compression: Qdrant uses binary quantization (opens new window) which converts any numeric vector embedding into a vector of boolean values. It provides up to 40x better search performance.
- Multitenancy Support: Having a single collection with payload-based partitioning is called multitenancy (opens new window). Qdrant supports it for multi-user sharing of instances.
- I/O Uring (opens new window): Qdrant provides support for
io_uringto improve the throughput to combat the OS system calls overhead.
With a clear understanding of what MyScaleDB and Qdrant offer, let's now focus on the key differences. These distinctions will help you determine which database aligns best with your specific needs and priorities, from performance to unique features.
# Hosting Flexibility: A Key Consideration for Vector Databases
When evaluating database solutions, hosting emerges as a critical factor with far-reaching implications for performance, scalability, and ease of management. The right hosting option ensures your database can gracefully handle fluctuating workloads, maintain high availability, and minimize administrative overhead.
In terms of hosting, both MyScaleDB and Qdrant provide open-source versions, cloud-based solutions and on-premise solutions. The cloud hosting provides both free and paid tiers, as we will shortly see in detail.
# Cloud Hosting
For MyScaleDB cloud (opens new window), you can start from a free pod supporting 5 million 768-dimensional vectors. Sign up here (opens new window) and checkout MyScaleDBDB QuickStart (opens new window) for more instructions.
Qdrant gives you a 1GB free forever cluster without any upfront costs. To start using Qdrant visit the cloud Quickstart (opens new window).
# On-Premise
For on-premise solution, Docker image is a general option. We can launch the MyScaleDB Docker image as:
docker run --name MyScaleDB --net=host MyScaleDB/MyScaleDB:1.6
Then connect to the database using ClickHouse client:
docker exec -it MyScaleDBdb clickhouse-client
Similarly, Qdrant can also be run locally using the Docker as:
docker run -p 6333:6333 qdrant/qdrant
# Core Functionalities
While hosting options lay the foundation for database accessibility and scalability, it's the core functionalities that truly differentiate MyScaleDB and Qdrant. This section dissects the essential features of each platform, providing insights into how they handle the intricacies of vector-based data processing.
Understanding these features will help you see how each database handles key tasks in vector-based data processing and which one might best meet your specific needs.
# Query Language and API Support
The choice of query language and available API support play a crucial role in developer productivity and ease of integration. Let's take a look how MyScaleDB and Qdrant address these aspects:
# Multi-Language Support:
- Qdrant: Qdrant boasts extensive multi-language support, catering to a wide range of developers with SDKs for Python (opens new window), Java (opens new window), Go (opens new window), .Net (opens new window), Rust (opens new window) and TypeScript/JavaScript (opens new window). This breadth of language support ensures seamless integration with various technology stacks.
- MyScaleDB: MyScaleDB provides SDKs for Python, Java, Go, and Node.JS (opens new window), offering solid support for popular programming languages.
While both databases offer respectable multi-language support, MyScaleDB sets itself apart with its unique embrace of SQL. You can use traditional SQL queries with MyScaleDB, and it will work seamlessly with vector databases or even a combination of traditional and vector databases like this:
SELECT id, date, label,
distance(data, {target_row_data}) AS dist
FROM default.myscale_search
ORDER BY dist LIMIT 10
The distance method in MyScaleDB calculates the similarity between vectors by measuring the distance between a specified vector and all vectors stored in a particular column.
Note: If you like to work with SQL, then definitely MyScaleDB will be your choice.
# Supported Data Types
The ability to handle diverse data types is essential for any database, and vector databases are no exception. Let's compare MyScaleDB and Qdrant in terms of their supported data types:
# Qdrant's Flexible JSON Approach
Qdrant leverages the flexibility of JSON payloads, allowing it to store and query a wide range of data types, including:
- Keywords: For text-based searches and filtering.
- Integers and Floats: For numerical data and range queries.
- Nested Objects and Arrays: For representing complex data structures.
This JSON-centric approach provides flexibility in data modeling and accommodates various use cases.
# MyScaleDB's SQL-Powered Versatility:
MyScaleDB takes data type support a step further by leveraging its full SQL compatibility. This enables it to manage not only vector data but also a wide array of traditional data types, including:
- Structured Data: Traditional relational data types like integers, floats, strings, dates, etc.
- JSON: For handling semi-structured data and nested objects.
- Geospatial Data: For location-based queries and spatial analysis.
- Time-Series Data: For storing and analyzing time-stamped data.
MyScaleDB's ability to handle both vector data and diverse traditional data types within a single platform offers a significant advantage. This unified approach simplifies data management, eliminates data silos, and enables powerful queries that span different data types.
Below is an example table showing the variety of columns that MyScaleDB can manage, including vector data.
CREATE TABLE default.wiki_abstract_mini(
`id` UInt64,
`body` String,
`title` String,
`url` String,
`body_vector` Array(Float32),
CONSTRAINT check_length CHECK length(body_vector) = 768
)
ENGINE = MergeTree
ORDER BY id
SETTINGS index_granularity = 128;
This SQL command creates a table with structured and vectorize data, enforces a vector size of 768, and optimizes queries by ordering by id.
TL;DR: Both databases effectively support a wide range of numeric and text data types, but MyScaleDB takes it further with its advanced SQL compatibility, powerful OLAP capabilities, and comprehensive support for complex data structures like geospatial and time-series data.
# Indexing
For indexing, Qdrant uses the Hierarchical Navigable Small World (HNSW) (opens new window) algorithm, which, while effective for standard vector searches, struggles with filtered search operations.
MyScaleDB addresses this limitation by introducing the Multi-Scale Tree Graph (MSTG) algorithm. MSTG combines hierarchical tree clustering with graph-based search, significantly enhancing retrieval speed and performance. This makes it highly efficient for both standard and complex filtered vector search operations.
By the way, both MyScaleDB and Qdrant support multi-vector search.
Note: MSTG outperforms contemporary indexing algorithms, giving MyScaleDB a significant advantage in both standard and filtered vector searches.
# Full Text Search
Full-text search (opens new window) is available in both Qdrant (starting from version 0.10.0) and MyScaleDB. Qdrant implements full-text search by supporting tokenization and indexing of text fields, allowing it to search and filter based on specific words or phrases.

MyScaleDB, on the other hand, uses the Tantivy library, which leverages the BM25 algorithm for accurate and efficient document retrieval.
# Qdrant Example
Here is an example of making a full-text index (usually called payload index in their terminology) in Qdrant,
from qdrant_client import QdrantClient, models
client = QdrantClient(url="<http://localhost:6333>")
client.create_payload_index(
collection_name="{collection_name}",
field_name="name_of_the_field_to_index",
field_schema=models.TextIndexParams(
type="text",
tokenizer=models.TokenizerType.WORD,
min_token_len=2,
max_token_len=15,
lowercase=True,
),
)
This code snippet in Qdrant sets up a text index by tokenizing a text field based on parameters like word length and case sensitivity.
# MyScaleDB Example
In MyScaleDB example, we are using the stem tokenizer with English stop words, which can improve search accuracy by focusing on the root form of words. In this case, we are using the table en_wiki_abstract (it has been used throughout this example (opens new window) if you want to see in detail).
ALTER TABLE default.en_wiki_abstract
ADD INDEX body_idx (body)
TYPE fts('{"body":{"tokenizer":{"type":"stem", "stop_word_filters":["english"]}}}');
Note: There isn’t much to differentiate the two in terms of full-text search, as both offer effective solutions.
# Filtered Search
MyScaleDB optimizes filtered vector search through its MSTG algorithm, along with bitmasking techniques. This combination, coupled with ClickHouse's advanced indexing and parallel processing capabilities, allows MyScaleDB to efficiently handle large datasets. By utilizing a pre-filtering strategy, MyScaleDB narrows down the dataset before the main vector search, ensuring that only the most relevant data is processed, which significantly boosts both performance and accuracy.
Qdrant uses a filterable version of the HNSW algorithm (opens new window), which applies filters during the search process to ensure that only relevant nodes in the search graph are considered.
# Geo Search
Both MyScaleDB and Qdrant support geo search. MyScaleDB has a number of geospatial functions (opens new window) to support the geo search. For example, this function finds the distance between two points on Earth (taken as a manifold):
greatCircleDistance(lon1Deg, lat1Deg, lon2Deg, lat2Deg)
# LLM APIs Integration
Arguably, the biggest application of vector searches is LLMs and RAGs. Both Qdrant and MyScaleDB have their back by supporting several LLM APIs integrations like LlamaIndex (opens new window), LangChain (opens new window) and Hugging Face (opens new window).
# Pricing
Both Qdrant and MyScaleDB adopt a freemium pricing model, offering free tiers suitable for experimentation and smaller projects, alongside more powerful paid tiers for demanding workloads. Importantly, both platforms allow users to explore their free offerings without requiring credit card information.
# Free tier
- Qdrant: Provides 1GB of storage capacity in its free tier.
- MyScaleDB: Offers a significantly more generous free tier, allowing storage of up to 5 million 768-dimensional vectors. To put this into perspective, achieving this storage capacity on Qdrant's platform would require a paid plan costing approximately $275 per month.
# Paid tier
For paid tier, both Qdrant and MyScaleDB provide all 3 types of cloud hostings: GCP, Azure and AWS. Usually, Azure and AWS have the higher costs, while GCP is the most economical option available.
For the paid tier, we will compare Qdrant’s GCP hosting with MyScaleDB. For MyScaleDB, we will consider both capacity and performance optimized options, using a consistent vector size of 768 dimensions for all comparisons..
| Capacity | Qdrant ($)/hour | Nodes | MyScaleDB Capacity Optimized ($)/hour | Pods | MyScaleDB Performance Optimized ($)/hour | Pods |
|---|---|---|---|---|---|---|
| 10 Million | 0.75 | 1 | 0.09 | 1 | 0.33 | 2 |
| --- | --- | --- | --- | --- | --- | --- |
| 20 Million | 1.5 | 1 | 0.19 | 2 | 0.67 | 4 |
| 40 Million | 3.02 | 2 | 0.38 | 4 | 1.33 | 8 |
| 80 Million | 4.52 | 3 | 0.76 | 8 | 2.67 | 16 |
| 160 Million | 9.05 | 6 | 1.51 | 16 | 5.33 | 32 |
| 320 Million | 16.58 | 11 | 3.02 | 32 | 10.66 | 64 |
In the capacity-optimized pods of MyScaleDB, we get 10 million vectors per pod, while performance-optimized setting provides lower latency and as a result, we have more pods for storage. We can see that even performance-optimized pods of MyScaleDB are way cheaper than the Qdrant’s most economical setting.
Another trend we note that MyScaleDB has a linear scaling factor, while Qdrant has more of an assymetrical pattern, as we can see in this graph.
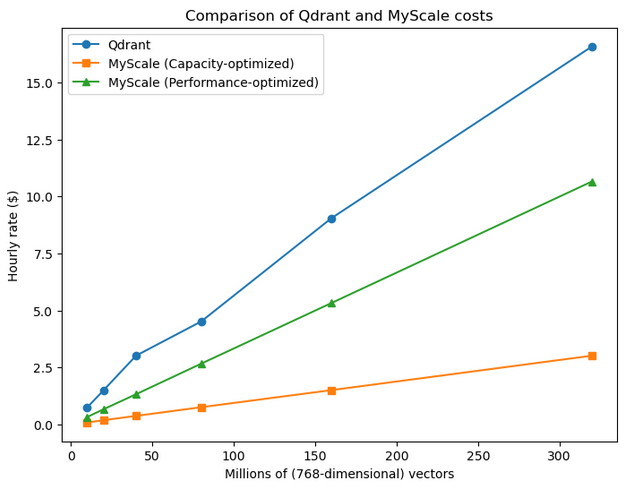
Note: When it comes to pricing - free or paid tier, there’s no match to MyScaleDB.
# Benchmarking
While the previous feature comparisons provide valuable insights, objective benchmarking offers a more concrete understanding of MyScaleDB and Qdrant's performance capabilities.
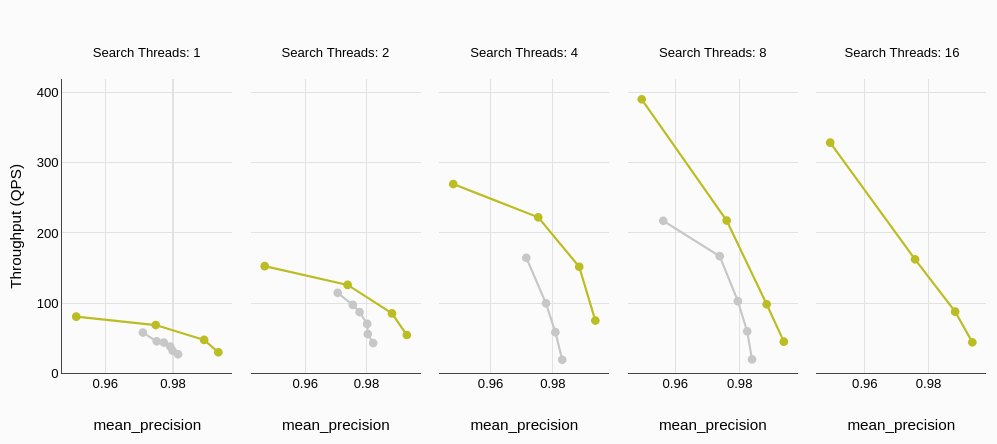
# Throughput (Queries Per Second)
Throughput, typically measured in Queries Per Second (QPS), directly reflects a database's ability to handle concurrent requests efficiently. The benchmark results clearly demonstrate MyScaleDB's superior throughput compared to Qdrant. Moreover, the performance gap widens significantly as the number of concurrent threads increases, showcasing MyScaleDB's exceptional scalability under heavy workloads.
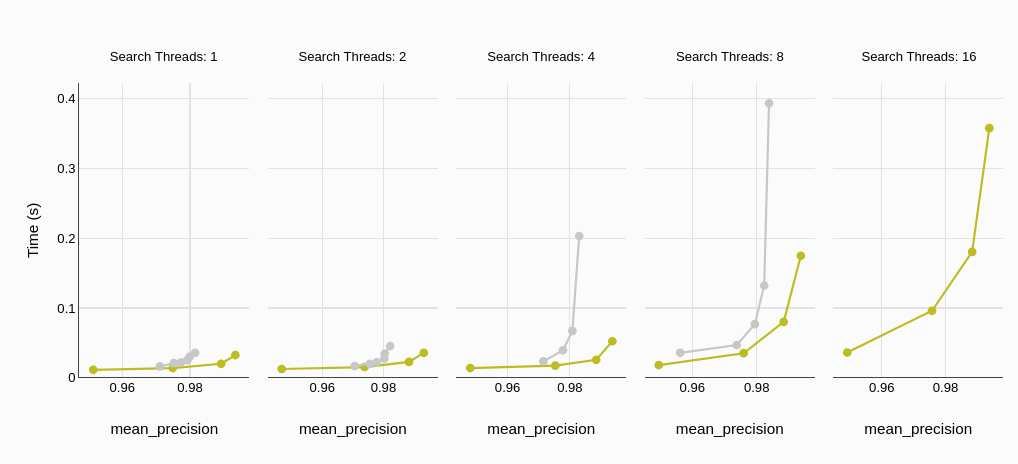
# Average Query Latency
Average query latency, measured in milliseconds or seconds, represents the average time a database takes to process a query and return results. Lower latency translates to faster response times, a critical factor in real-time applications and user experience.
The benchmark results consistently show MyScaleDB achieving significantly lower average query latency compared to Qdrant. This trend holds true across varying thread counts, indicating MyScaleDB's ability to maintain low latency even under high concurrency.
We see similar trends in P95 (95 percentile) latency too, further emphasizing on the low latency of MyScaleDB for the practical applications.
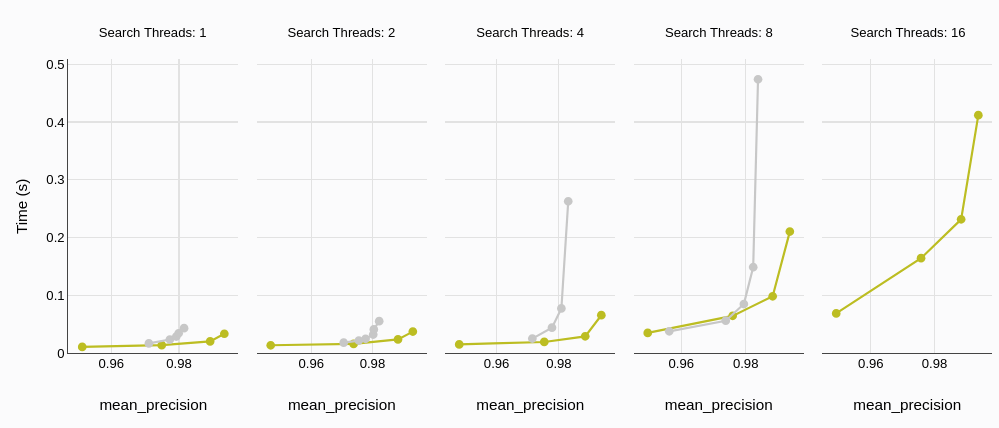
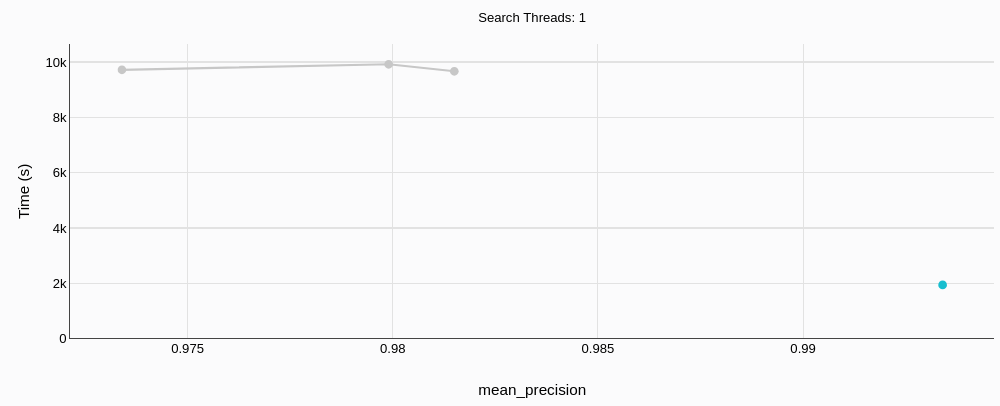
# Build time
MyScaleDB (green; that little dot in the right-bottom corner) not only has a better precision, but does so almost 5x faster.
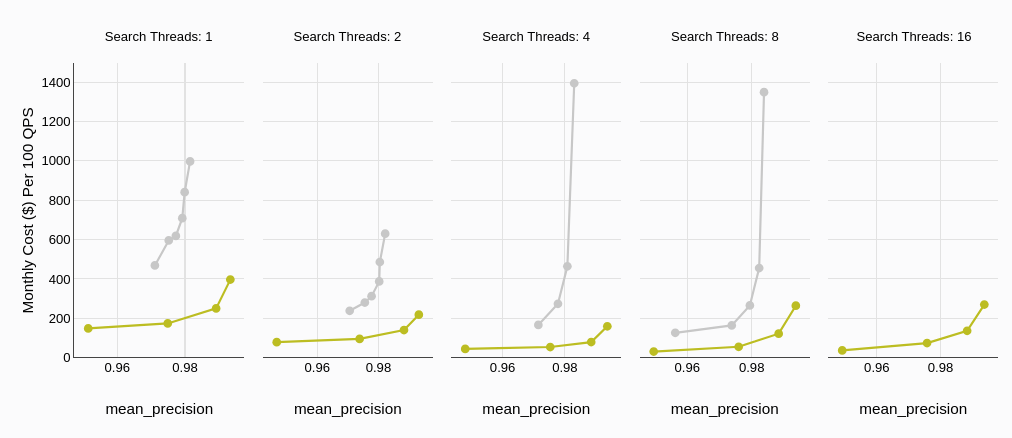
# Monthly Cost
Cost-effectiveness plays a crucial role in choosing the right database solution. As highlighted in the pricing section, MyScaleDB generally offers a more affordable option compared to Qdrant, especially when considering its generous free tier.
This graph further explains it in terms of the search threads. We can see that Qdrant’s cost (grey) exhibits a steep upward trend as the number of search threads increases. In contrast, MyScaleDB maintains a significantly lower cost profile, remaining relatively stable even with higher thread counts.

# Conclusion
Both Qdrant and MyScaleDB stand out as prominent contenders in the rapidly evolving landscape of vector databases. Qdrant, with its longer presence in the market, benefits from wider adoption and offers compelling features like support for sparse vectors and efficient quantization techniques.
However, MyScaleDB emerges as a powerful alternative, boasting significant advantages in key areas:
- Performance and Scalability: MyScaleDB consistently outperforms Qdrant in benchmarks, demonstrating superior throughput, lower latency, and impressive scalability for demanding workloads.
- Cost-Effectiveness: MyScaleDB offers a compelling value proposition with its generous free tier and significantly lower costs for paid plans, especially for high-concurrency scenarios.
- Unified Data Management: MyScaleDB's ability to manage both vector and diverse traditional data types within a single platform simplifies data pipelines and enables powerful cross-data queries.
- SQL-Powered Simplicity: Leveraging the familiarity and expressiveness of SQL, MyScaleDB streamlines development and empowers users to interact with vector data using a widely adopted language.
Ultimately, the optimal choice depends on your specific requirements and priorities. If broad language support and specialized features like sparse vector handling are paramount, Qdrant might be a suitable option. However, if performance, scalability, cost-effectiveness, and unified data management are critical considerations, MyScaleDB emerges as the clear frontrunner.
We encourage you to carefully evaluate your needs and leverage the insights from this comparison to make an informed decision that aligns with your unique data processing and application requirements.



