
Vector databases are on the rise and their applications are everywhere. They are super fast (imagine searching through billions of entries in a fraction of a second), and require much fewer resources (you don’t need any GPUs). And despite all this, they have handsome performance and are reliable enough to be used in sectors like public health, finance and biometrics.
There are a number of vector databases available, and MyScale is a special one among them as an SQL-based vector database. Whether you are already a vector database user or new to them, making a choice among them can be tricky; it depends on many factors like pricing, scalability, availability of some particular features, some benchmarks and so on. To help users make a choice thoroughly, we have introduced this series of articles comparing different vector databases (opens new window). In this sequel, we will compare MyScale and Weaviate.
# A Brief Introduction to MyScale
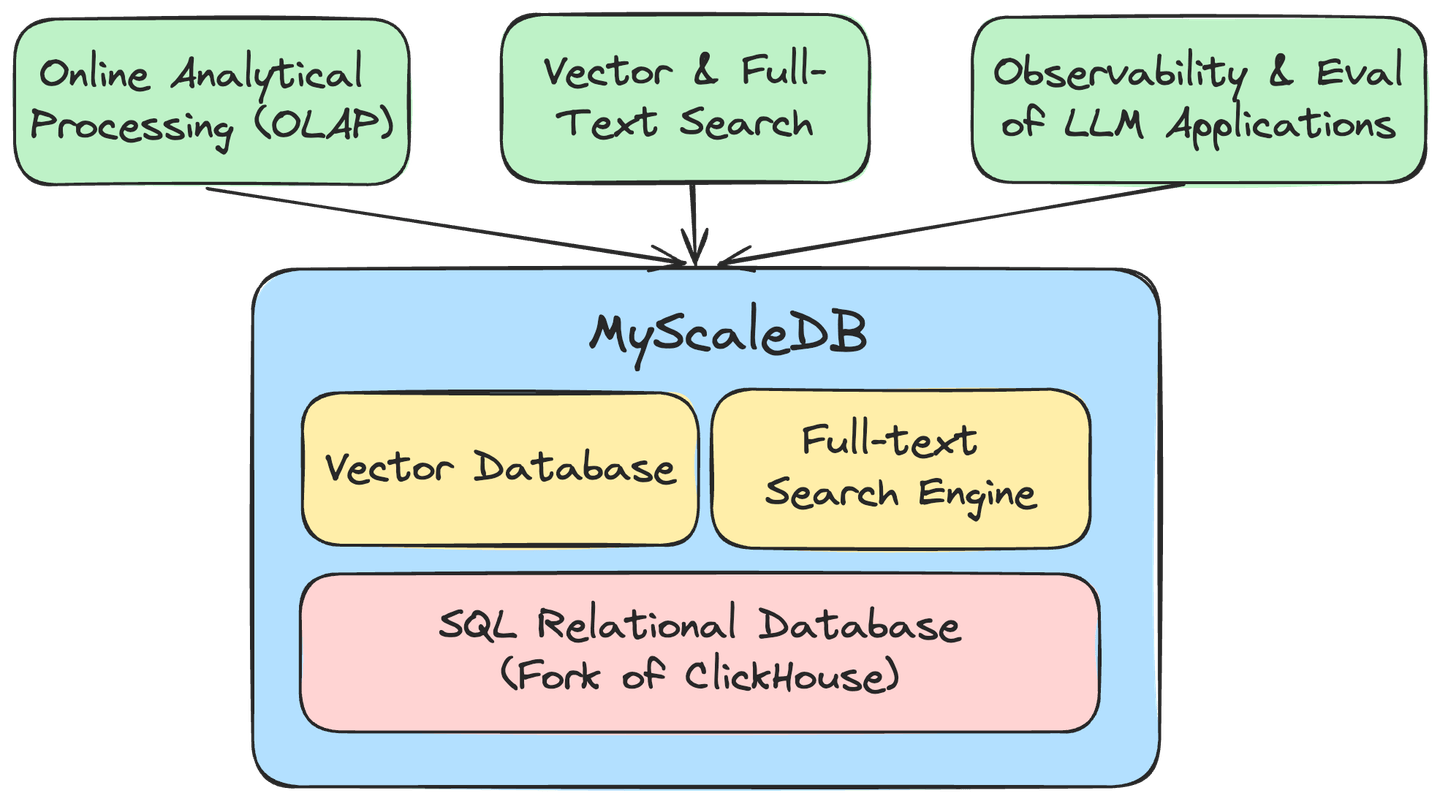
MyScale (opens new window) is an open-source, cloud-based database designed for AI-driven solutions. Built on ClickHouse and Tantivy, it combines the power of SQL, vector databases, and full-text search functionalities into a single platform. MyScale supports full SQL, including complex queries, making it both reliable and scalable for large-scale data management.
Optimized for AI applications, MyScale handles structured and vectorized data efficiently, allowing for robust analytical processing. Its inherited OLAP architecture from CilckHouse ensures lightning-fast performance and can perform searches on billions of vectors in milliseconds. Additionally, MyScale is highly accessible, requiring only SQL for interaction, simplifying its integration into your existing systems.
# What is Weaviate
Weaviate is an open-source (opens new window) vector database written in Go, designed to manage both objects and vectors. It is highly optimized for machine learning and AI applications, particularly those requiring fast vector searches. Weaviate offers both free and pay-as-you-go tiers, making it accessible for various projects.
The database excels in speed, performing nearest neighbor searches on millions of data points within milliseconds. This speed makes it a strong choice for tasks such as semantic search, recommendation systems, and classification. Weaviate also integrates easily with popular ML models, supporting a wide range of media types, including text and images, while offering scalability and cloud-native features.
Now we will begin the comparison in different aspects, starting from the hosting.
# Hosting
When hosting a vector database like Weaviate or MyScale, it's essential to consider the deployment environment carefully, even during the experimental phase. These databases can be self-hosted on local machines, but cloud-native hosting is often preferred for scalability and ease of use. Cloud platforms like AWS, Google Cloud, or Kubernetes offer flexible options for scaling based on your workload.
# Docker/On-premise
Both MyScale and Weaviate are open-source, so they can be run locally using Docker. It is quite helpful for small applications, some privacy-based applications or just trying out something for experimental purposes. You can run MyScale locally as:
docker run --name MyScale --net=host myscale/MyScale:1.6
For Weaviate, you can use the Docker compose as:
docker run -p 8080:8080 -p 50051:50051 cr.weaviate.io/semitechnologies/weaviate:1.27.0
# Cloud-based Hosting
Despite the availability of these docker-based solutions, there are a number of reasons why users prefer the cloud-based services:
- Better Resources
- Optimized Algorithms
- Scalability
Both Weaviate and MyScale provide free and paid cloud solutions, and the two options for paid services are:
- Capacity-optimized (default, cheaper)
- Performance-optimized (better performance, expensive)
# Core Functionalities
Now let’s step in the comparison of the core functionalities of the two databases, and each has its own merits.
# Query Language and API Support
- Both of them support clients in different languages, like Python, Node.JS, Go, etc.
- Both of them provide support for the GraphQL and REST APIs.
Weaviate: its latest version provides us the support for the gRPC API too. Also, it must be noted that the new Python and TypeScript clients for Weaviate aren’t stable yet.
MyScale: The real power of MyScale lies in the support for SQL. You can use traditional SQL to interact and manage the database.
# Metadata Support
Both MyScale and Weaviate support metadata. MyScale optimizes filtered vector search using its MSTG algorithm alongside ClickHouse's advanced indexing and parallel processing capabilities. Besides, a pre-filtering strategy is also adopted to narrow the dataset before the main vector search, enhancing performance and accuracy.
TL;DR:
Both have the support for metadata, while MyScale’s metadata filtering, thanks to ClickHouse’s scalability, doesn’t degrade in performance, even for the larger datasets.
# Supported Data Types
Both MyScale and Weaviate support the vectors obviously. They also support the advanced types like geoCoordinates.
Weaviate: has cross-reference type, which allows us to link different objects to another.
MyScale: supports all the SQL datatypes.
For example, here is a table having vector type to store the text embeddings, combined with primitive data types (for id and sentences ).
CREATE TABLE IF NOT EXISTS BookEmbeddings (
id UInt64,
sentences String,
embeddings Array(Float32),
CONSTRAINT check_data_length CHECK length(embeddings) = 1536
) ENGINE = MergeTree()
ORDER BY id;
MyScale has full SQL support and as a result, we can write quite complex queries, for example:
SELECT
myscale_movie.id,
myscale_movie.title,
myscale_rating.rating,
distance(
myscale_movie.embedding,
[0.00578, 0, ..., 0, 0.00984]
) AS dist
FROM
myscale_movie
INNER JOIN myscale_rating
ON myscale_rating.movieId = myscale_movie.id
WHERE
myscale_rating.rating > 4
ORDER BY
dist DESC
LIMIT 10;
TL;DR:
Both of MyScale and Weaviate support vector and respective datatypes. MyScale has a clear advantage of full SQL datatypes and SQL features.
# Scalability
While we will look at the pricing details in the latter part of this blog, its noteworthy that (under standard pricing), MyScale offers up to 320 million vectors (opens new window), while Weaviate’s scalability is limited as it doesn’t offer solutions beyond 50 million vectors (opens new window). It shows a serious limitation of Weaviate as having millions of vectors in a database is not uncommon.
# Indexing
Being open-source, both support a number of indexing algorithms like HNSW, FLAT and Dynamic.
Weaviate: its indexing was in experimental phase until recently.
MyScale: goes one-up on not only Weaviate but all popular vector databases by supporting the Multi-Scale Tree Graph (MSTG) (opens new window), an algorithm combining hierarchical tree clustering and graph-based search. It outperforms contemporary algorithms by providing faster searches with reduced resource consumption.
# Filtered Vector Search and Full-Text Search
MyScale optimizes filtered vector search (opens new window) through its MSTG algorithm. This approach, coupled with ClickHouse's advanced indexing and parallel processing capabilities, allows MyScale to handle large datasets efficiently. The pre-filtering strategy adopted by MyScale narrows down the dataset before the main vector search, ensuring that only the most relevant data is processed, thus enhancing both performance and accuracy.
Weaviate also supports vector searches, but its status on full-text searches is unclear. MyScale, on the other hand, supports both full-text searches and hybrid search (opens new window).
By the way, both MyScale (opens new window) and Weaviate support multi-vector search.
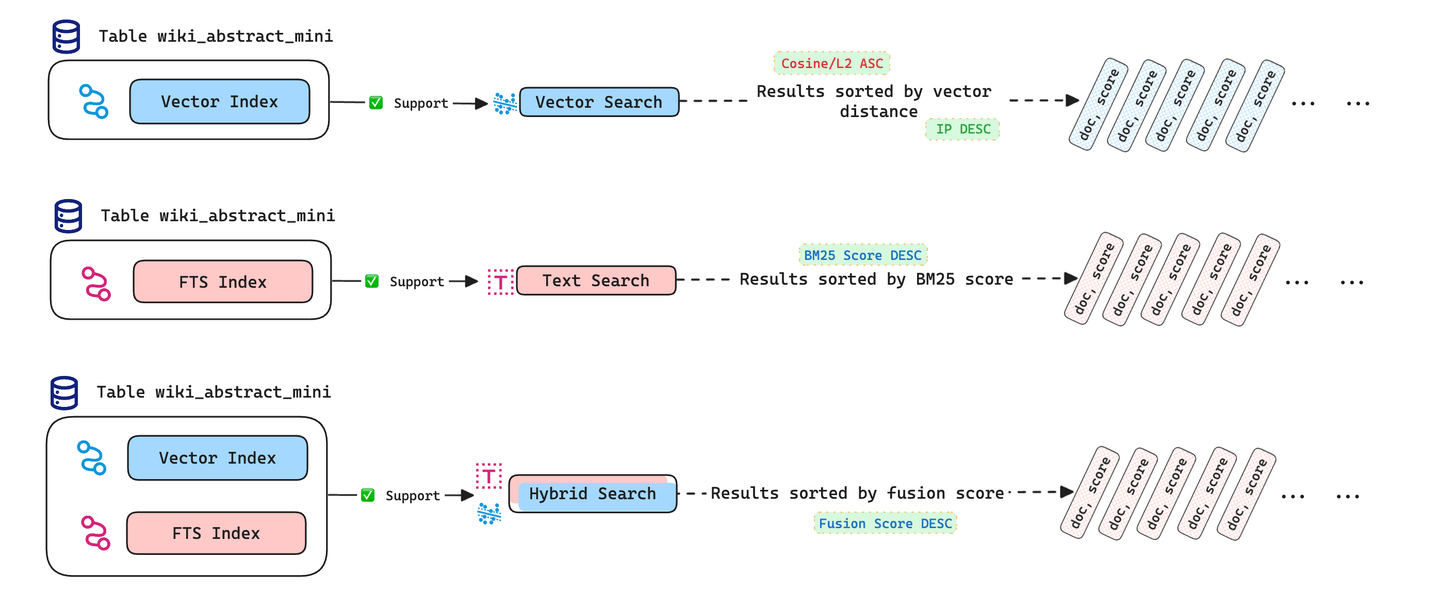
You can use the function HybridSearch()in MyScale, which combines the results of both full-text and vector searches to provide better results. The above image explains it pretty well for a given table wiki_abstract_mini.
# Geo Search
Geo search is something of great importance to not only maps and GIS applications but in many other applications. Even a simple application like FoodPanda or some grocery store may require it. However, Weaviate doesn’t provide it. MyScale has a number of geospatial functions (opens new window) to support the geo search. For example, greatCircleDistance() finds the distance between two points on Earth (taken as a manifold):
SELECT greatCircleDistance(31.5, 74.33, 25.30, 51.54)
--Output: 2,553,475.8
Here, we use this function to find the distance between two cities (Lahore and Doha) using the great circle formula (opens new window). The distance returned is in meters and as we can verify, it's correct (opens new window). Here, the difference of a few km is due to the selection of centers of the cities.
Weaviate also supports geo data and while it doesn’t feature a geospatial search function yet, it allows us to filter on the basis of geo-coordinates to search within a specific area. Like this code takes the desired location’s coordinates and looks within 500m circle.
import weaviate
from weaviate.classes.query import Filter, GeoCoordinate
import os
client = weaviate.connect_to_local()
response = publications.query.fetch_objects(
filters=(
Filter
.by_property("headquartersGeoLocation")
.within_geo_range(
coordinate=GeoCoordinate(
latitude=30.5,
longitude=78.3
),
distance=500 # In meters
)
),
)
# LLM APIs Integration
- Both MyScale and Weaviate support a number of LLM APIs like OpenAI, LLamaIndex, LangChain, etc.
- Both of them also support Cohere models and DSPy for automated prompting.
As an example, here’s a code integrating LangChain with MyScale using OpenAI embeddings.
from langchain_community.document_loaders import TextLoader
from langchain_community.vectorstores import MyScale
loader = TextLoader("../../how_to/state_of_the_union.txt")
documents = loader.load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
docs = text_splitter.split_documents(documents)
embeddings = OpenAIEmbeddings()
for i, d in enumerate(docs):
d.metadata = {"doc_id": i}
docsearch = MyScale.from_documents(docs, embeddings)
This code takes a text file, loads the documents and gets their embeddings using the OpenAI model. Further, it will upload the data to the MyScale cluster. If the index is absent, it will be created, and if it already exists, it will be reused.
# Observability of the LLM App Performance
MyScale Telemetry (opens new window) is a specialized tool designed to enhance the observability of large language models (LLMs) by capturing and storing trace data from applications, particularly those built with LangChain. This trace data is stored in MyScaleDB (or ClickHouse) and can be analyzed for debugging and performance optimization.
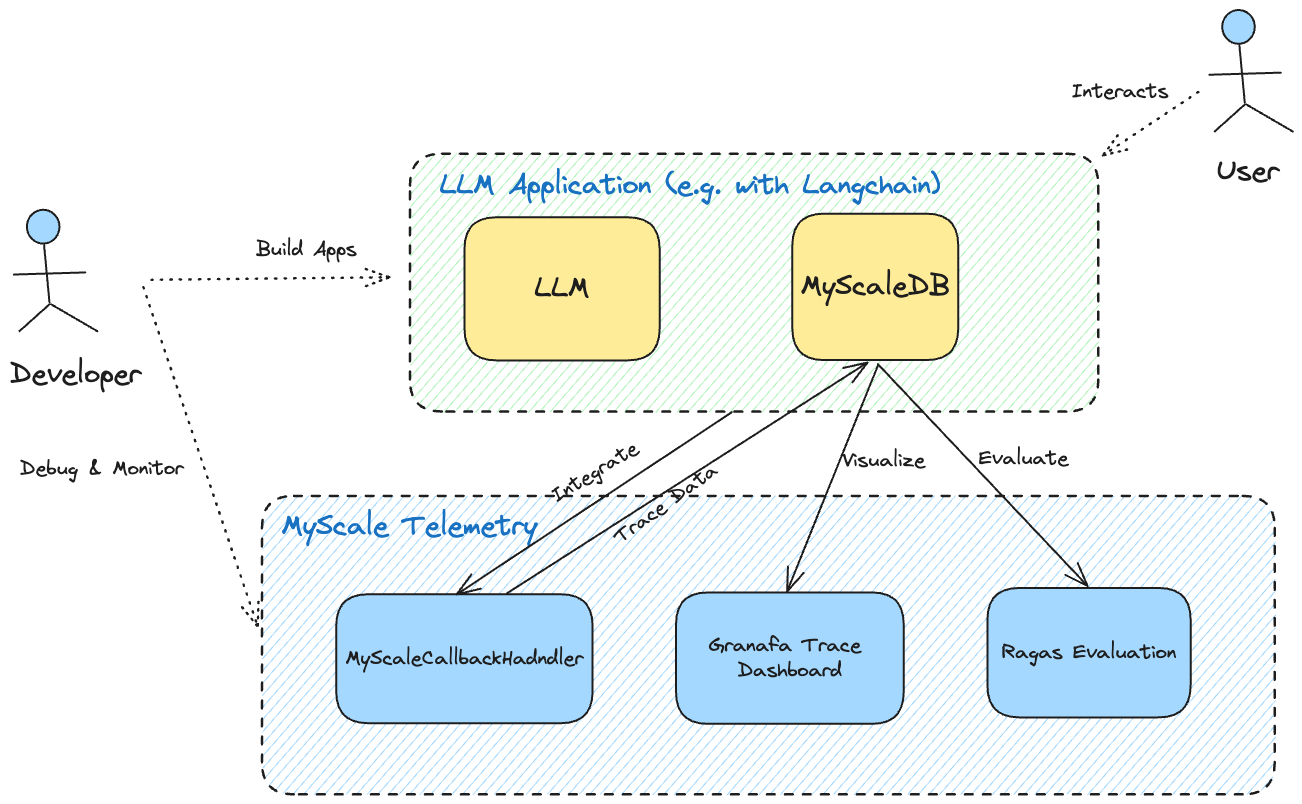
Developers can monitor the behavior of their LLMs through visual dashboards, such as the Grafana Trace Dashboard, which simplifies the process of diagnosing issues and evaluating application performance in real-time. This tool makes it easier to gain deep insights into the runtime behavior of LLMs with minimal performance overhead
# Pricing
In the end, every solution is constrained by two ultimate parameters: price and efficiency. For efficiency, we will benchmark them shortly. Firstly, let’s compare them economically.
Both Weaviate and MyScale provide free and paid tiers. We will provide a brief (and to the point) comparison of both here.
# Free tier
Weaviate’s free tier is restricted to 14-days-only sandbox. After 14 days, users have to choose between either buying the service or discarding their further usage. On the other hand, MyScale offers free storage for up to 5 million 768-dimensional vectors and it is not limited to any number of days (as long as cluster is not inactive for 7 days).
# Paid tier
Free tiers are good for experimentation, but in the end, you have to deploy solutions on dedicated servers, which requires money.
MyScale has two paid tiers:
- Capacity-optimized pod
- Performance-optimized pod
In the capacity-optimized pods, you will get 10 million vectors per pod, while the performance-optimized setting provides lower latency (5 million vectors per pod).
Weaviate provides 3 options:
- Serverless cloud
- Enterprise cloud
- Bring your own cloud.
In the following table, we provide the comparison of both (capacity and performance optimized) versions of MyScale with Weaviate’s serverless cloud (the least expensive one). The pricing for other two is unavailable publicly on their website and hence left. Weaviate has a serious limitation that it doesn’t provide support beyond 50 million vectors.
| Capacity | Weaviate Default ($)/hour | Weaviate High Performance | MyScale Capacity Optimized ($)/hour | Pods | MyScale Performance Optimized ($)/hour | Pods |
|---|---|---|---|---|---|---|
| 10 Million | 1.021 | 2.95 | 0.09 | 1 | 0.33 | 2 |
| 20 Million | 2.042 | 5.9 | 0.19 | 2 | 0.67 | 4 |
| 40 Million | 4.084 | 11.8 | 0.38 | 4 | 1.33 | 8 |
| 80 Million | - | - | 0.76 | 8 | 2.67 | 16 |
| 160 Million | - | - | 1.51 | 16 | 5.33 | 32 |
| 320 Million | - | - | 3.02 | 32 | 10.66 | 64 |
As we can see, MyScale is way lighter on the pocket than either default or high-performance Weaviate. Even the performance optimized is good 3x times cheaper than the default Weaviate clusters.
TL;DR: When it comes to value for the money, there’s no competition with MyScale. For example, MyScale’s 80 million vectors hosting costs less than Weaviate’s 10 million hosting. Plus, it has the advantage of better scalability too.
# Benchmarking
It would be a fair comparison to benchmark the two in terms of some basic attributes. For benchmarking, we will compare MyScale (using MSTG) vs these two different configurations of Weaviate. To make the comparison unbiased, we will use the latest versions of Weaviate:
- Weaviate’s older version
- Weaviate’s new version (v1.23.3)
# Throughput
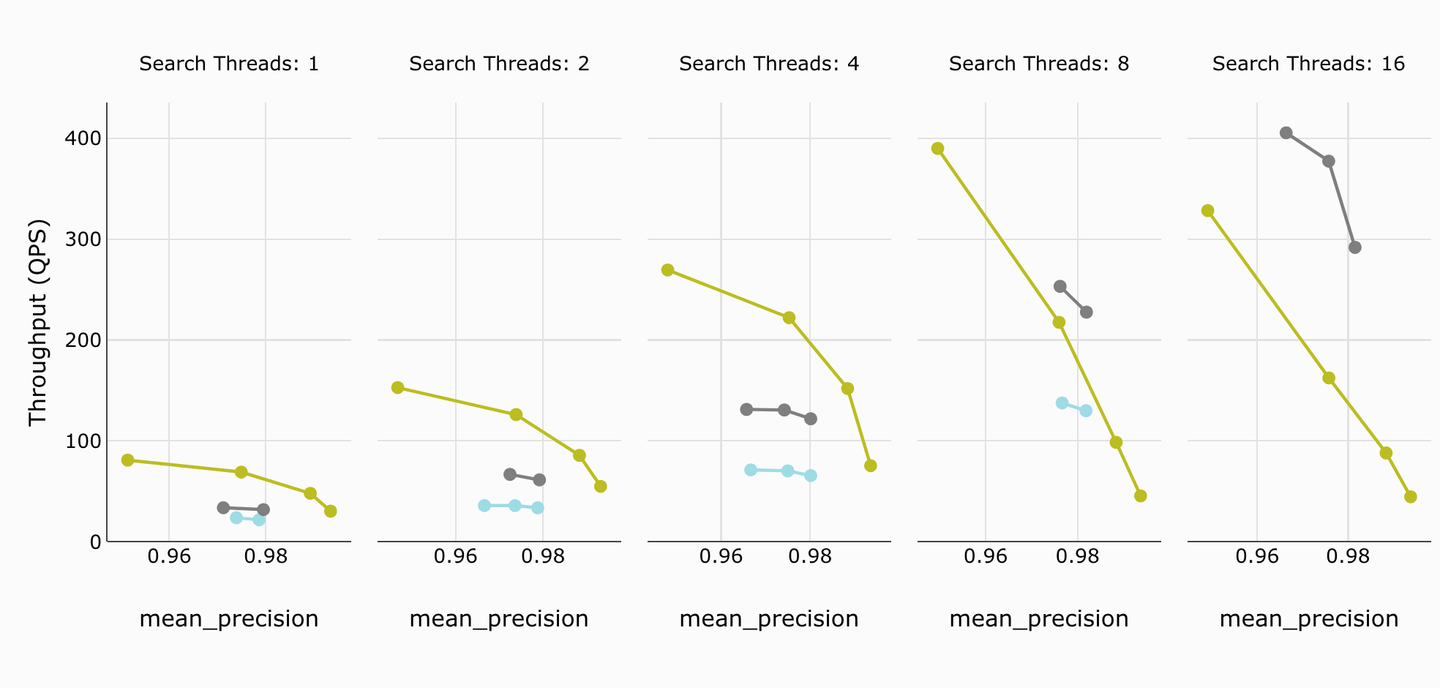
The number of queries per second is a good basic measure of a vector database. We can clearly see that MyScale (darker lime green) outperforms classical Weaviate. Weaviate v1.23 (dark grey color) outperforms MyScale only for 8 or more threads. MyScale still has a clear edge in terms of the mean precision, as we can see.
TL;DR:
MyScale outperforms both old and new versions of Weaviate upto 4 threads. For more threads, Weaviate’s latest version outperforms, though MyScale has a better precision.
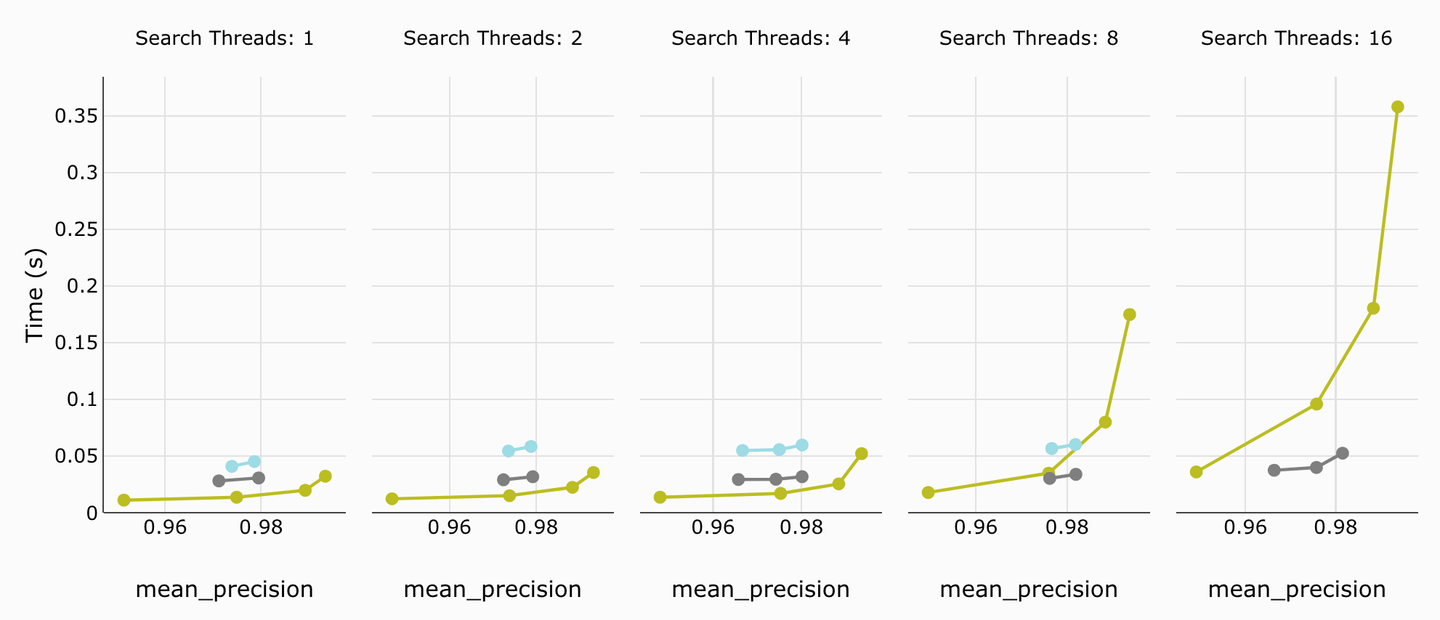
# Average Query Latency
Average query latency can be defined as the time (the lower, the better) it takes the database on average to return the query results. MyScale outperforms Weaviate nodes comfortably here. Only for the 16 threads does Weaviate show an edge over MyScale.
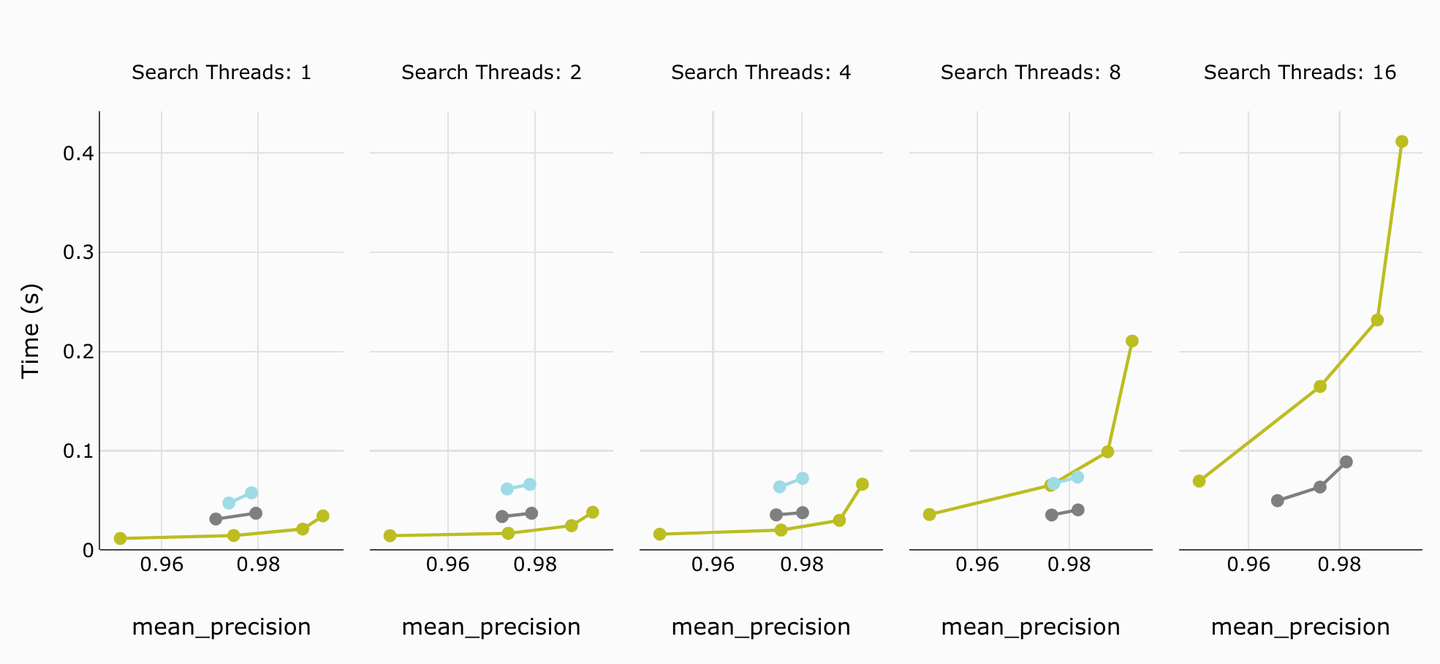
# P95 Latency
We have similar results in P95 latency too. Once threads are beyond 8, Weaviate’s latest version shows better (faster) latency over MyScale, while for the legacy version, MyScale outperforms Weaviate by a fair margin.
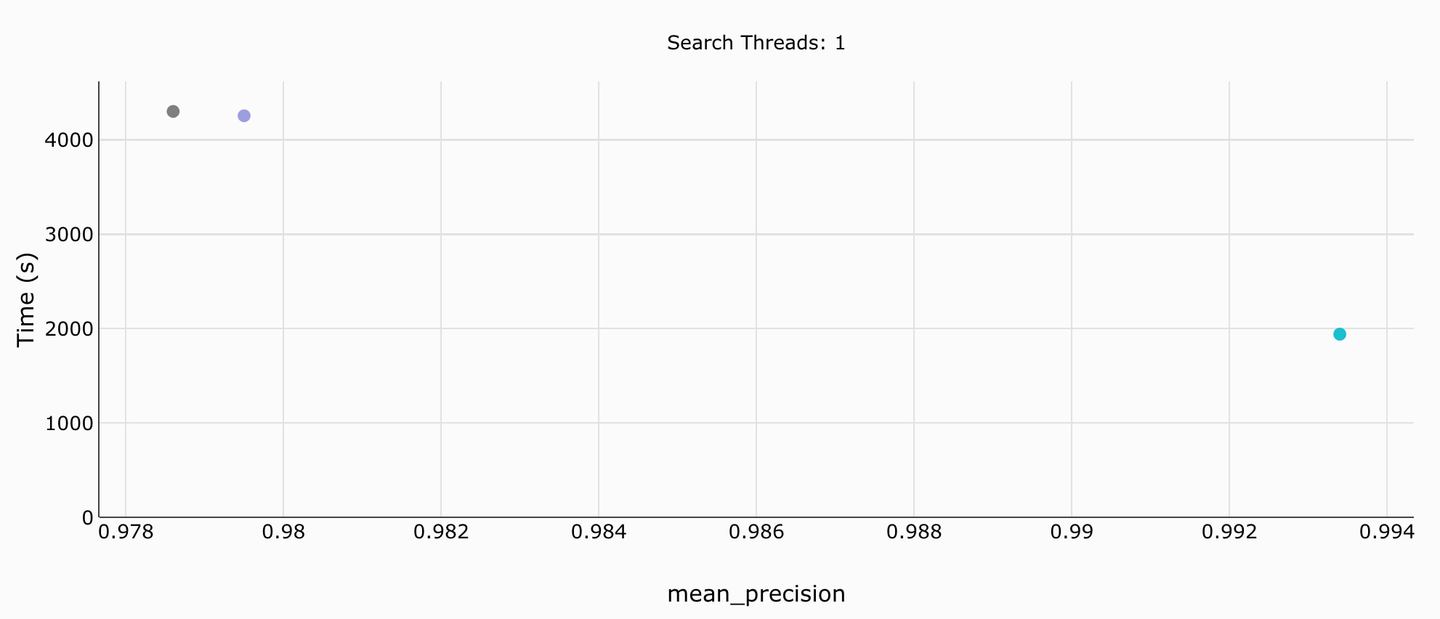
# Data Ingestion Time
This benchmarking is restricted to just a single thread, hence we will show a single plot here. MyScale (in sea green here) comfortably outperforms Weaviate in terms of the time it takes to upload and build it. The gap between their mean precision is also quite striking (every fraction close to 100% matters).
# Monthly Cost
Even the monthly cost of legacy Weaviate is way north of MyScale’s (right at the bottom in every graph). Only for 8 or16 threads they get close to each other.
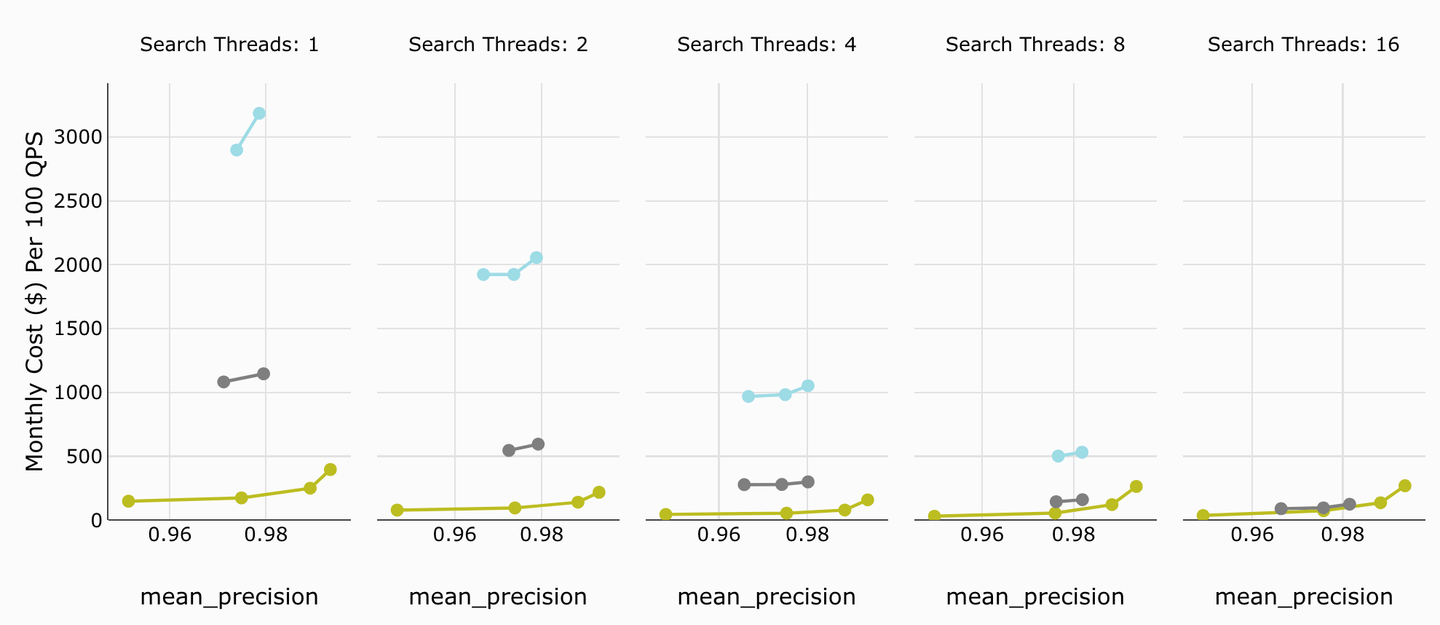
TL;DR:
MyScale provides you with the best value for your money by providing minimal monthly cost per QPS.

# Conclusion
In the rapidly expanding field of vector databases, both MyScale and Weaviate present strong solutions, each with its unique strengths. Deciding between the two requires careful consideration of project-specific requirements. MyScale excels in scalability, cost-efficiency, and latency, making it a compelling choice for large-scale applications that need to manage extensive structured and vector data while benefiting from its full SQL support. This ability to handle complex queries efficiently and integrate seamlessly with traditional data types gives MyScale an edge in many enterprise environments.
On the other hand, Weaviate, built for AI-first applications, offers flexibility with its support for a variety of machine learning models and embeddings. Its robust API, modular architecture, and real-time updates make it a great fit for projects requiring dynamic interaction with unstructured data. While both databases support multiple programming languages, MyScale's full SQL compatibility positions it as a more comprehensive solution for projects that require both advanced data analytics and rapid vector search.



