
Vector databases and vector searches are rapidly gaining popularity due to their speed and scalability. Unlike traditional machine learning models that require extensive training, vector searches can be performed swiftly using basic similarity measures like Euclidean distance and cosine similarity in a vector database. This makes them highly scalable and more cost-effective compared to ML-based models.
As the use of vector databases continues to grow, it's natural to seek out the most suitable database based on specific needs, considering various factors like throughput and cost. To help users make informed decisions, we are launching a series of articles that provide detailed comparisons of different vector databases. In our last blog, we conducted a thorough comparison between MyScale and Pinecone (opens new window). This time, we'll dive into an in-depth comparison of MyScale and Zilliz.
# Introduction to MyScale and Zilliz
# MyScale
MyScale is a cloud-based database designed specifically for AI applications and solutions, leveraging the open-source, highly scalable ClickHouse database. Key advantages of using MyScale include:
- Supports and manages the analytical processing of both structured and vectorized data on a unified platform.
- Utilizes advanced OLAP database architecture to execute operations on vectorized data with exceptional speed.
- Requires only SQL as the programming language to interact with MyScale.
# Zilliz
Zilliz, based on the open-source Milvus project, is a powerful cloud-native vector database designed for high-performance similarity search and machine learning. While Milvus serves as the backbone, Zilliz offers a fully managed cloud service with both free and pay-as-you-go tiers, tailored for users who need scalable vector management without the overhead of infrastructure management.
In this blog, we'll compare the cloud offerings of MyScale and Zilliz to help you understand which one might be better suited for your needs. Let's start the comparison from the hosting.
# Hosting
Hosting is a critical aspect to consider when choosing a database solution, as it significantly impacts performance, scalability, and management. A robust hosting option ensures that your database can handle varying loads, remain accessible, and be easily maintained. Additionally, understanding hosting options helps determine whether you need to deploy the database locally using your own resources or opt for a cloud-hosted service.
In terms of hosting, both MyScale and Zilliz provide open-source versions, cloud-based solutions and the on-premise solutions. The cloud hosting provides both free and paid tiers, as we will shortly see in detail.
For the on-premise solution, Docker image is a general option. We can launch the MyScale Docker image as:
docker run --name MyScale --net=host myscale/MyScale:1.6
For Zilliz, we can use the Docker compose as:
curl <https://github.com/milvus-io/milvus/releases/download/v2.0.2/milvus-standalone-docker-compose.yml> -o docker-compose.yml
docker-compose up -d
# Core Functionalities
Now we will begin the comparison in terms of the core functionalities of the two databases.
# Query Language and API Support
Both Zilliz and MyScale offer support for clients in various programming languages, including Python, Node.js, and Go. Zilliz additionally supports C++, .Net (partially), RESTful, and Ruby too.
However, the real power of MyScale lies in its support for SQL. You can use traditional SQL queries with MyScale, and it will work seamlessly with vector databases or even a combination of traditional and vector databases.
TL;DR:
Both Zilliz and MyScale offer SDKs in various languages, but MyScale has a distinct advantage with its full SQL support.
# Metadata Support
Zilliz supports regular expressions in metadata filtering. It also supports a new scalar inverted index in its latest version (based on Milvus 2.4).
MyScaleDB supports metadata filtering through its integration with ClickHouse, which provides robust indexing and parallel processing capabilities. This allows MyScaleDB to perform high-performance, accurate filtered searches, especially when dealing with large-scale datasets. Besides, a pre-filtering strategy is also adopted to narrow the dataset before the main vector search, enhancing performance and accuracy.
TL;DR:
Zilliz has the edge of regular expressions in metadata filtering, while MyScale’s metadata filtering, thanks to ClickHouse’s scalability doesn’t degrade in performance, even for the larger datasets.
# Supported Data types
Both MyScale and Zilliz support vector data obviously. Zilliz’s latest version also includes support for Sparse and Binary vectors. MyScale, however, excels with its full SQL support, enabling it to handle all the SQL data types. For example, here is a table having vector (body_vector) and some other data types (like UInt64 and String in this case) as its attributes.
CREATE TABLE default.wiki_abstract_mini(
`id` UInt64,
`body` String,
`title` String,
`url` String,
`body_vector` Array(Float32),
CONSTRAINT check_length CHECK length(body_vector) = 1024
)
ENGINE = MergeTree
ORDER BY id
SETTINGS index_granularity = 128;
TL;DR:
Zilliz has the advantage of sparse vector support, while MyScale has a far superior advantage of full SQL data types.
# Indexing
Both MyScale and Zilliz support many indexing algorithms like HNSW, IVF (and its variants), FLAT, etc. Zilliz provides autoindex, which uses features like dynamic caching and dynamic quantization. Autoindex is not an entirely new indexing algorithm and uses these supported indexing algorithms in the background.
MyScale goes one-up on not only Zilliz but all popular vector databases by supporting the Multi-Scale Tree Graph (MSTG), an algorithm combining hierarchical tree clustering and graph-based search. MSTG outperforms contemporary algorithms by providing faster searches with reduced resource consumption.
# Filtered Vector Search and Full-Text Search
MyScale optimizes filtered vector search through its Multi-Scale Tree Graph (MSTG) algorithm, along with bitmasking techniques. This combination, coupled with ClickHouse's advanced indexing and parallel processing capabilities, allows MyScale to efficiently handle large datasets. By utilizing a pre-filtering strategy, MyScale narrows down the dataset before the main vector search, ensuring that only the most relevant data is processed, which significantly boosts both performance and accuracy.
Zilliz, on the other hand, also leverages bitmasks to manage and apply filter conditions effectively across large datasets. This approach allows Zilliz to perform complex filtering operations with minimal impact on performance.
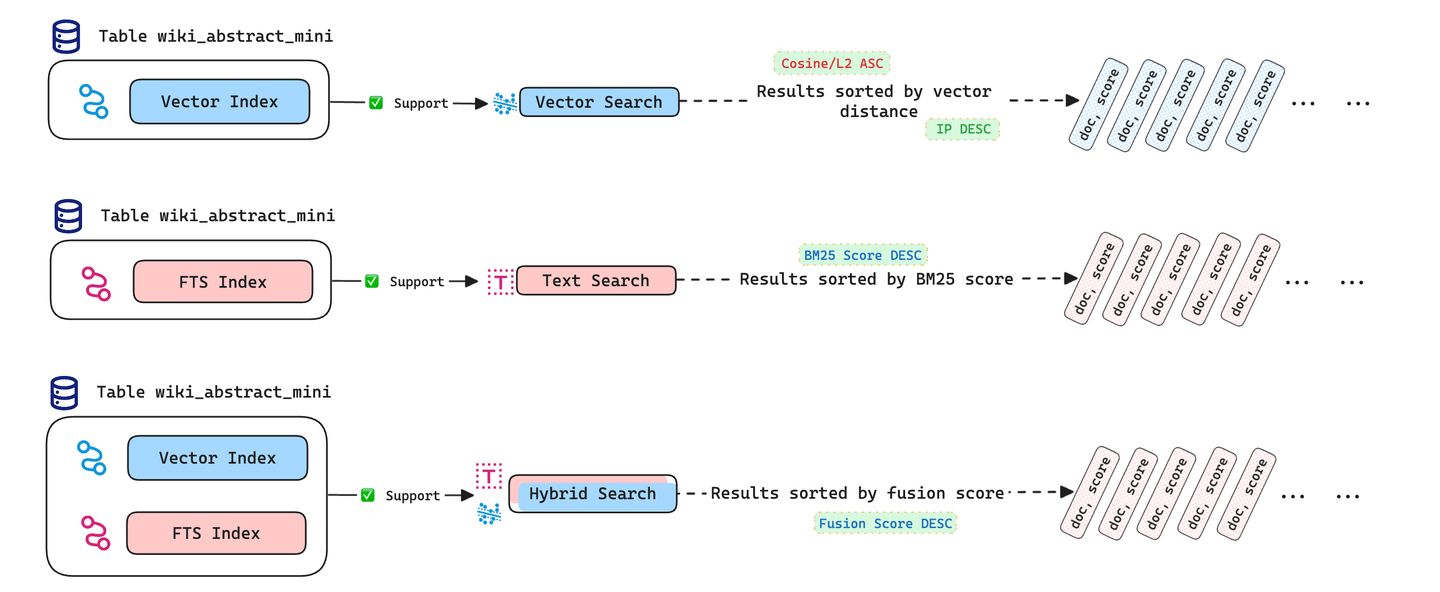
Both databases, thanks to Tantivy, are rich in search functionalities. They support the full-text search, which most of the other vector databases don’t support. Apparently, nothing to separate the two as both of them support the hybrid search (opens new window) as well. Though performing it on MyScale is much easier using the function HybridSearch(). It combines the results of both full-text and vector searches to provide better results. The above image explains it pretty well for a given table wiki_abstract_mini.
# Multi-vector Search
Both MyScale and Zilliz support multi-vector search. Additionally, Zilliz offers grouping search, where entities stored in multiple vectors can be grouped together in the search results for consolidated outcomes. Similarly, MyScale supports grouping search through the GROUP BY clause in SQL. This allows users to aggregate and group search results efficiently, making it easier to handle and analyze large datasets within MyScale.
# Geo Search
Geo search is something of great importance to not only maps and GIS applications but in many other applications. Even a simple application like FoodPanda or some grocery store may require it. While Zilliz doesn’t provide it, MyScale has a number of geospatial functions (opens new window) to support the geo search. For example, this function finds the distance between two points on Earth (taken as a manifold):
greatCircleDistance(lon1Deg, lat1Deg, lon2Deg, lat2Deg)
# LLM APIs Integration
Both MyScale and Zilliz support a number of LLM APIs like OpenAI, LLamaIndex, LangChain, etc. Both of them also support Cohere models and DSPy for automated prompting. As an example, here’s a code integrating LangChain with MyScale.
from langchain_community.vectorstores import MyScale
docsearch = MyScale.from_documents(docs,embeddings)
output= docsearch.similarity_search("How LLMs operate?",3)
# Pricing
In the end, every solution is constrained by two ultimate parameters: price and efficiency. For efficiency, we will benchmark them shortly. Firstly, we will compare them economically.
Both Zilliz and MyScale provide free and paid tiers. I will provide a brief (and to the point) comparison of both here.
# Free tier
Zilliz’s free tier supports two collections up to 0.5M 768-dimensional vectors (with GCP hosting; Azure and AWS are available only in the dedicated servers).
On the other hand, MyScale offers free storage for up to 5 million 768-dimensional vectors, which means 10x more than a collection’s capacity or 5x more than the combined capacity of the two collections. This is significantly higher than Zilliz’s free tier (equal to 1CU of capacity optimization in the paid tier), making MyScale a more attractive option for users who need to manage larger datasets without initial costs.
# Paid tier
Free tiers are good for experimentation, but in the end, we have to deploy our solutions on dedicated servers, which requires money. How valuable is MyScale or Zilliz for your investment will be analyzed here.
Note:
Zilliz’s physical nodes are known as a Computing Uni (CU), while MyScale’s is known as a Pod (and will be referred henceforth accordingly).
Both Zilliz and MyScale provide two types of paid hosting:
- Capacity optimized: Aims at having larger storage per pod/CU. MyScale provides 10 million vectors per pod while Zilliz provides up to 5 million vectors per CU.
- Performance optimized: It is for the applications prioritizing performance (lower latency, higher QPS). Here, MyScale provides up to 5 million vectors per pod. Zilliz provides up to 1.5 million vectors per CU.
If you are unsure about which one to choose, go for the capacity-optimized hosting.
In a data-driven world, it would be useful to show the exact figures as it would enable you to make a comparison much easily. For comparison, we will use vector dimensions of 768, assume a month of 30 days ****and it will be GCP hosting, unless stated otherwise.
# Serverless Zilliz
For serverless Zilliz hosting (which uses virtual CUs), we will assume 1M read and 1M write operations in a month across all the settings.
| Vector Capacity | Hourly Rate |
|---|---|
| 1 million | 0.09$ |
| --- | --- |
| 5 million | 0.21$ |
| 10 million | 0.31$ |
| 20 million | 0.47$ |
| 40 million | 0.74$ |
| 80 million | 1.15$ |
# Capacity Optimization
For capacity-optimized CUs, Zilliz provides 5 million per CU and MyScale provides 10 million per pod. This gap translates to a much lower cost per hour for MyScale.
| Vectors Capacity | Zilliz ($) | Computing Units (CUs) | MyScale ($) | Pods |
|---|---|---|---|---|
| 10 Million | 0.276 | 2 | 0.094 | 1 |
| --- | --- | --- | --- | --- |
| 20 Million | 0.55 | 4 | 0.19 | 2 |
| 40 Million | 1.1 | 8 | 0.38 | 4 |
| 80 Million | 2.2 | 16 | 0.76 | 8 |
# Performance Optimization
While we discussed above that MyScale provides 5 million per pod in the performance-optimized settings, which is more than 3x more than the limit provided by Zilliz (1.5 million per pod), there’s much more to that. Zilliz charges extra CUs (apparently for no reason). If you calculate the number of CUs needed for - say 10 million vectors, they should be:
1.510=6.67≈7
But it shows you 8 CUs. Same for the 20 million, where it should be charging 14 but charging an extra couple of CUs. Finally, it fixes it for 40 million to charge you the exact number of CUs (which still falls way short of the hourly charges for MyScale’s respective solution).
| Vectors Capacity | Zilliz | CUs | MyScale | Pods |
|---|---|---|---|---|
| 5 Million | 0.55 | 4 | 0.17 | 1 |
| --- | --- | --- | --- | --- |
| 10 Million | 1.1 | 8 (should be 7) | 0.33 | 2 |
| 20 Million | 2.2 | 16 (should be 14) | 0.67 | 4 |
| 40 Million | 3.84 | 28 | 1.33 | 8 |
| 80 Million | 7.68 | 56 | 2.67 | 16 |
TL;DR:
When it comes to value for the money, there’s no competition with MyScale. It provides 2x and more than 3x vectors for the capacity and performance-optimized tiers than Zilliz - all at a (still) lower per-hour rate.
# Benchmarking
It would be a fair comparison to benchmark the two in terms of some basic attributes. For benchmarking, we will use MyScale (using MSTG) vs these two different configurations of Zilliz. To give the users an unbiased comparison, we will use the latest versions of Zilliz:
- 2024-Capacity optimized (1 CU)
- 2024-Performance optimized (4 CUs)
# Throughput
The number of queries per second is a good basic measure of a vector database. We can clearly see that MyScale (darker lime green) outperforms Zilliz with single computing units. Zilliz with multiple units (orange color) outperforms MyScale in terms of QPS. MyScale, thanks to precision tuning, can reach higher precision though.
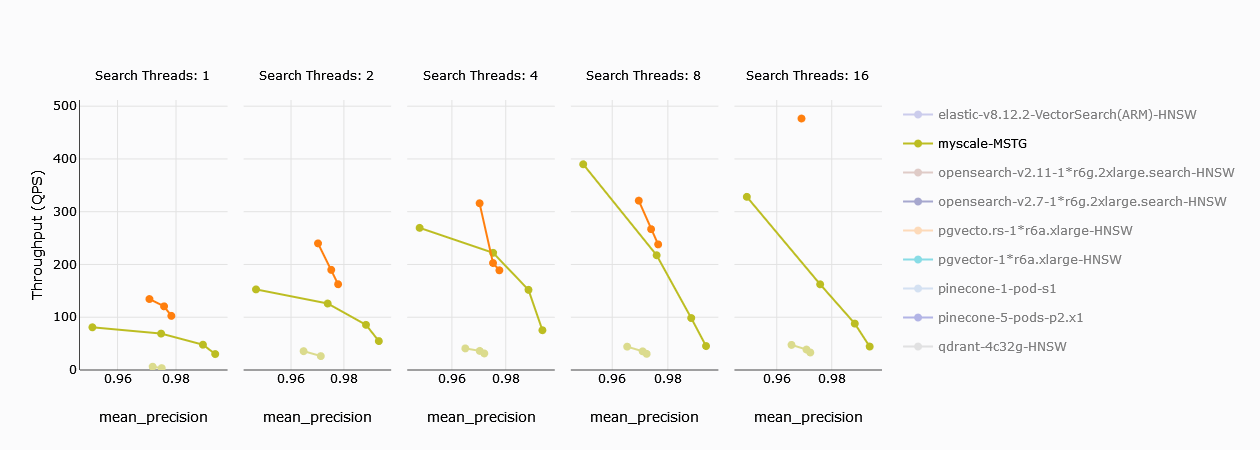
TL;DR:
MyScale outperforms Zilliz with a single computing unit. For 4 units, Zilliz outperforms, though MyScale has better precision.
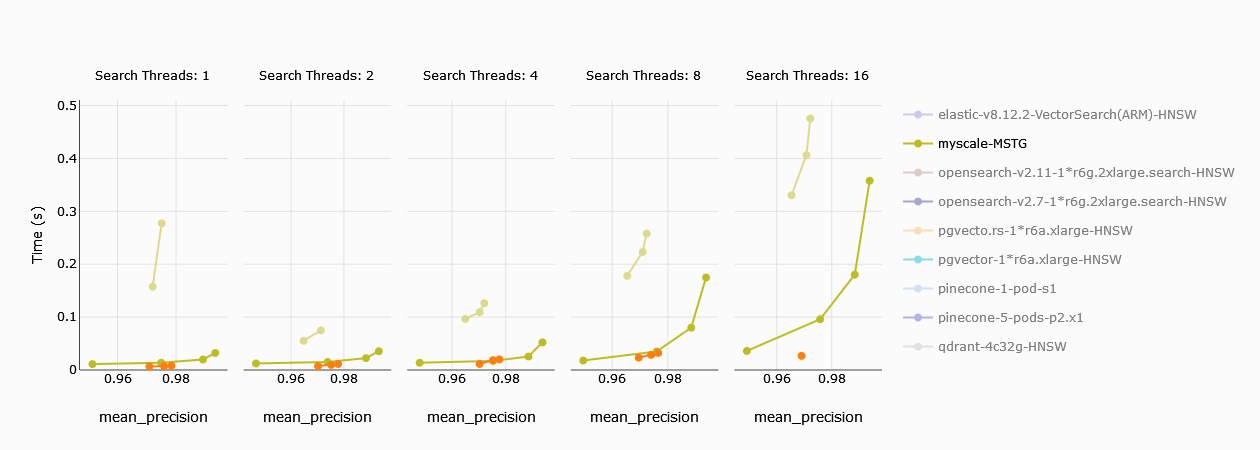
# Average Query Latency
Average query latency can be defined as the time (the lower, the better) it takes the database on average to return the query results. MyScale outperforms the single computing unit Zilliz nodes comfortably here. Even for the higher CUs, query latency is of the same order for both MyScale and Zilliz. For 16 threads, Zilliz’s 4CU node shows some improvement over MyScale.
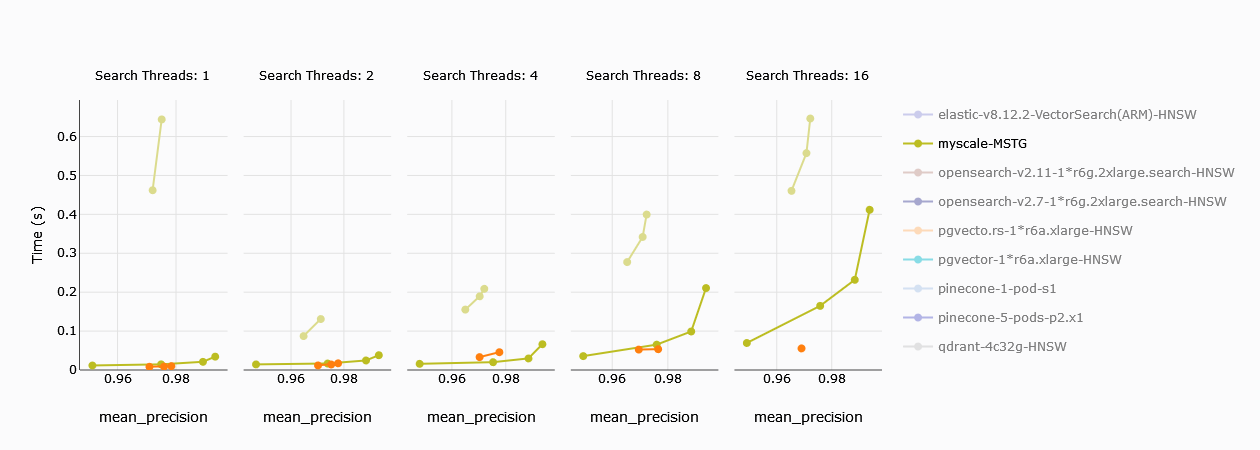
# P95 Latency
We have similar results in P95 latency too. Once threads are beyond 8, Zilliz’s 4CU shows better (faster) latency over MyScale, while for the single CU, MyScale outperforms Zilliz by a fair margin.
# Data Ingestion Time
This benchmarking is restricted to just a single thread, hence we will show a single plot here. MyScale (in sea green here) comfortably outperforms Zilliz in terms of the time it takes to upload and build it.
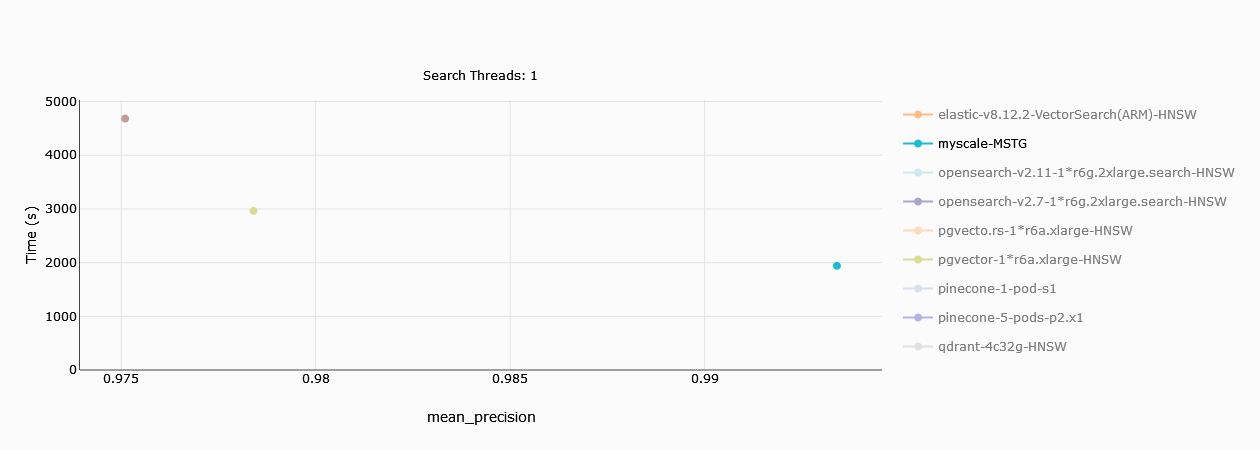
# Monthly Cost Comparison
For a single computing unit, Zilliz is comparable to MyScale (still lagging though) in terms of the monthly cost (per 100 QPS), but 4 CU setups is way more expensive than MyScale.
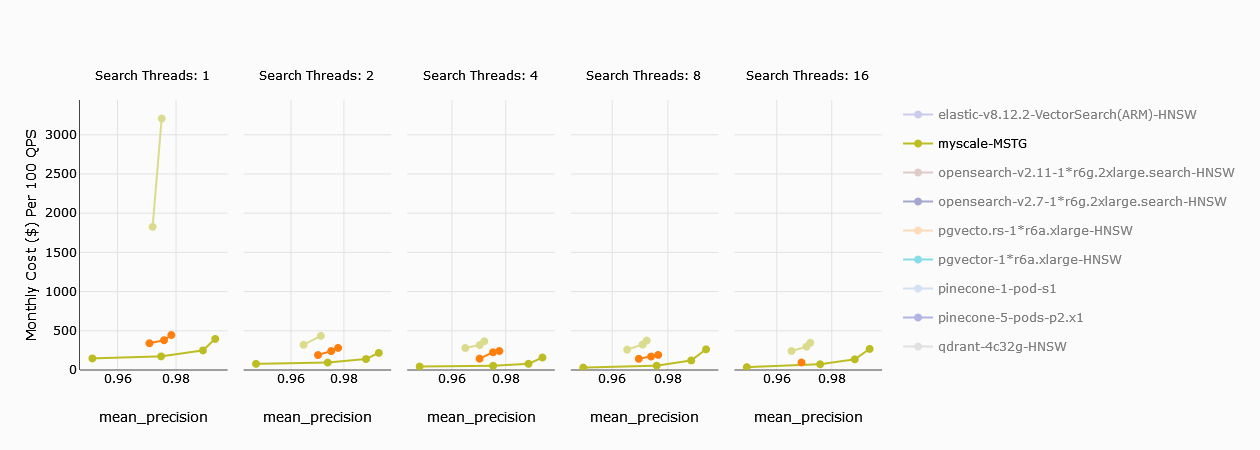
TL;DR:
MyScale provides you with the best value for cost efficiency by providing minimal monthly cost per QPS.

# Conclusion
If you have a generous budget, both Zilliz and MyScale offer competitive features, making it challenging to choose between them depending on specific user needs.
However, when it comes to cost-effectiveness, MyScale stands out. While Zilliz’s latest release includes advanced features like multi-vector search and support for sparse vectors, these enhancements are still in beta and do not offset the significant pricing gap.
MyScale offers better value, particularly in its paid tiers.Additionally, it offers other compelling advantages, such as full SQL support, the superior MSTG indexing algorithm, and more generous free tiers. These factors make MyScale a more attractive option for users prioritizing both performance and budget.



