
Generative AI’s (GenAI) iteration speed is growing exponentially. One outcome is that the context window — the number of tokens a large language model (LLM) can use at one time to generate a response — is also expanding rapidly.
Google Gemini 1.5 Pro, released in February 2024, set a record for the longest context window to date: 1 million tokens, equivalent to 1 hour of video or 700,000 words. Gemini's outstanding performance in handling long contexts led some people to proclaim that "retrieval-augmented generation (RAG) is dead." LLMs are already very powerful retrievers, they said, so why spend time building a weak retriever and dealing with RAG-related issues like chunking, embedding, and indexing?
The increased context window started a debate: With these improvements, is RAG still needed? Or might it soon become obsolete?
# How RAG Works
LLMs are constantly pushing the boundaries of what machines can understand and achieve, but they have been limited by issues such as difficulty responding accurately to unseen data or being up to date with the latest information. These gave rise to hallucinations, which RAG was developed (opens new window) to address.
RAG combines the power of LLMs with external knowledge sources to produce more informed and accurate responses. When a user query is received, the RAG system initially processes the text to understand its context and intent. Then it retrieves data relevant to the user’s query from a knowledge base (opens new window) and passes it, along with the query, to the LLM as context. Instead of passing the entire knowledge base, it passes only the relevant data because LLMs have a contextual limit (opens new window), the amount of text a model can consider or understand at once.
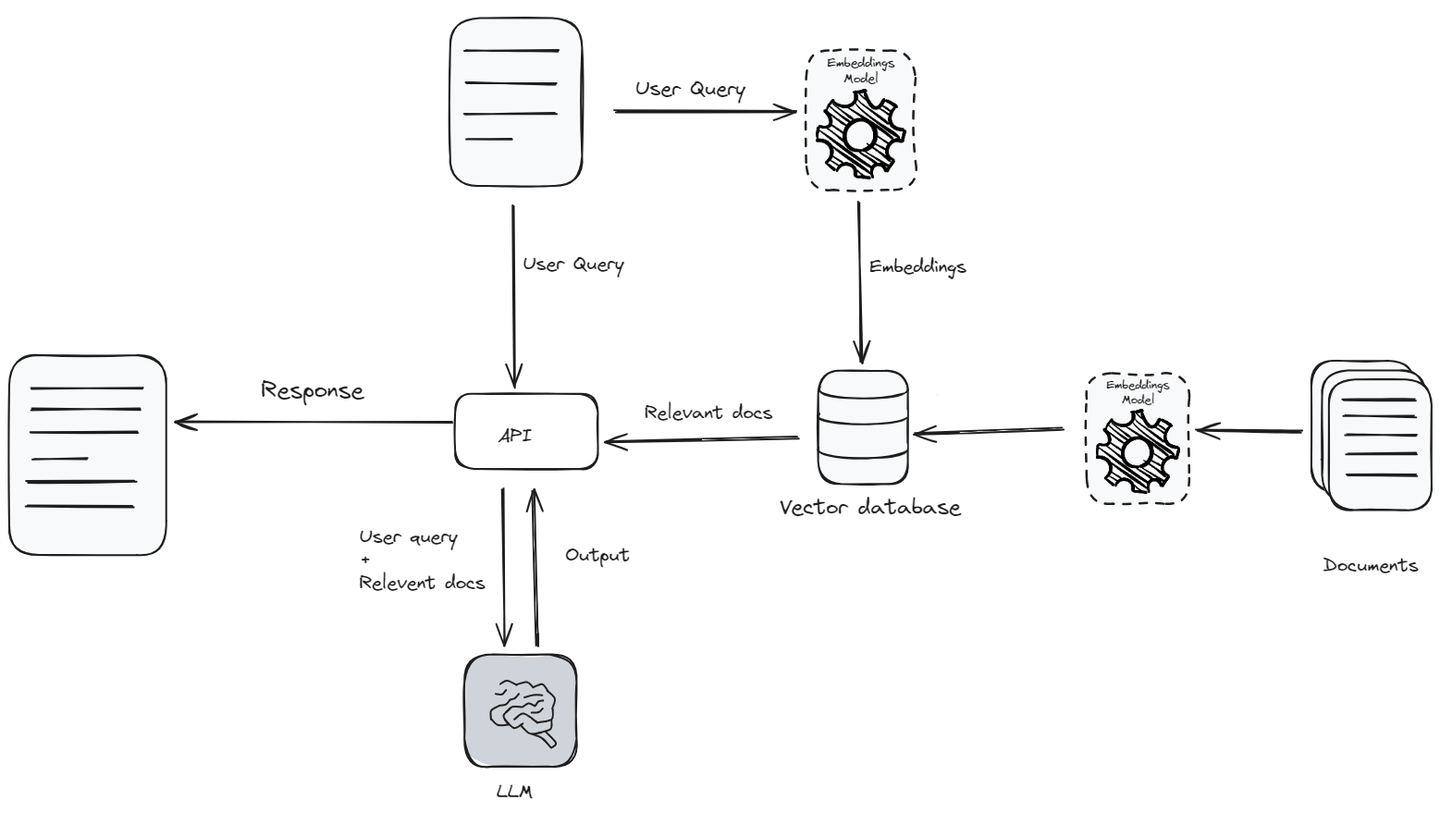
First, the query (opens new window) is converted into vector embeddings (opens new window) using an embedding model (opens new window). This embedding vector is then compared against a database of document vectors, identifying the most relevant documents. These relevant documents are fetched and combined with the original query to provide a rich context for the LLM to generate a more accurate response. This hybrid approach enables the model to use up-to-date information from external sources, allowing LLMs to generate more informed and accurate responses.
# Why Long Context Windows Might Be the End of RAG
The continuous increase in LLMs’ contextual window will directly impact how these models ingest and generate responses. By increasing the amount of text LLMs can process at one time, these extended contextual windows enhance the model's ability to understand more comprehensive narratives and complex ideas, improving the overall quality and relevance of generated responses. This improves LLMs’ ability to keep track of longer texts, allowing them to grasp a context and its finer details more effectively. Consequently, as LLMs become more adept at handling and integrating extensive context, the reliance on RAG for enhancing response accuracy and relevancy may decrease.
# Accuracy
RAG improves the model’s ability by providing relevant documents as a context based on a similarity score (opens new window). However, RAG doesn't adapt or learn from the context in real-time. Instead, it retrieves documents that appear similar to the user's query, which may not always be the most contextually appropriate, potentially leading to less accurate responses.
On the other hand, by utilizing the long contextual window of a language model by stuffing all the data inside it, an LLM’s attention mechanism (opens new window) can generate better answers. The attention mechanism within a language model focuses on the different parts of the provided context to generate a precise response. Furthermore, this mechanism can be fine-tuned (opens new window). By adjusting the LLM model to reduce loss, it gets progressively better, resulting in more accurate and contextually relevant responses.
# Information Retrieval
When retrieving information from a knowledge base to enhance LLM responses, it's always hard to find complete and relevant data for the contextual window. There's continual uncertainty about whether the retrieved data completely answers the user’s query. This situation can cause inefficiencies and errors if the information chosen isn’t enough and doesn’t align well with the user's actual intentions or the context of the conversation.
# External Storage
Traditionally, LLMs couldn't handle massive amounts of information simultaneously because they were limited in how much context they could process. But their newly enhanced capabilities allow them to handle extensive data directly, eliminating the need for separate storage per query. This streamlines architecture speeds access to external databases and boosts AI efficiency.
# Why RAG Will Stick Around
Expanded contextual windows in LLMs may provide a model with deeper insights, but it also brings challenges such as higher computational costs and efficiency. RAG tackles these challenges by selectively retrieving only the most relevant information, which helps optimize performance and accuracy.
# Complex RAG Will Persist
There’s no doubt that simple RAG, where data is chunked into fixed-length documents and retrieved based on similarity, is fading. However, the complex RAG systems are not just persisting but evolving significantly.
Complex RAG includes a broader range of capabilities such as query rewriting (opens new window), data cleaning (opens new window), reflection (opens new window), optimized vector search (opens new window), graph search (opens new window), rerankers (opens new window) and more sophisticated chunking techniques. These enhancements are not only refining RAG’s functionality but also scaling its capabilities.
# Performance Beyond Context Length
While expanding the contextual window in LLMs to include millions of tokens looks promising, the practical implementations are still questionable due to several factors including time, efficiency, and cost.
Time: As the size of the contextual window increases, so does latency in response times. As you expand the size of the contextual window, the LLM takes more time to process a higher number of tokens, leading to delays and increased latency. Many LLM applications require quick responses. The added delay from processing larger text blocks can significantly hinder the LLM’s performance in real-time scenarios, creating a major bottleneck in the implementation of larger contextual windows.
Efficiency: Studies suggest that LLMs achieve better results when provided fewer, more relevant documents rather than large volumes of unfiltered data. A recent Stanford study (opens new window) found that state-of-the-art LLMs often struggle to extract valuable information from their extensive context windows. The difficulty is particularly pronounced when critical data is buried in the middle of a large text block, causing LLMs to overlook important details and leading to inefficient data processing.
Cost: Expanding the size of the context window in LLMs results in higher computational costs. Processing a larger number of input tokens demands more resources, leading to increased operational expenses. For instance, in systems like ChatGPT, there is a focus on limiting the number of tokens processed to keep costs under control.
RAG optimizes each of these three factors directly. By passing only similar or related documents as context (rather than stuffing everything in) LLMs process information more quickly, which not only reduces latency but also improves the quality of responses and lowers the cost.
# Why Not Fine-Tuning
Besides using a larger contextual window, another alternative to RAG is fine-tuning. However, fine-tuning can be expensive and cumbersome. It's challenging to update an LLM every time new information comes in to make it up-to-date. Other issues with fine-tuning include:
- Training data limitations: No matter the advancements made in LLMs, there will always be contexts that were either unavailable at the time of training or not deemed relevant.
- Computational resources: To fine-tune an LLM on your data set and tailor it for specific tasks, you need high computational resources.
- Expertise needed: Developing and maintaining cutting-edge AI isn't for the faint of heart. You need specialized skills and knowledge that can be hard to come by.
Additional issues include gathering the data, making sure that the quality is good enough, and model deployment.
# Comparing RAG vs Fine-Tuning or Long Context Windows
Below is a comparative overview of RAG and fine-tuning or long context window techniques (because the latter two have similar characteristics, I have combined them in this chart). It highlights key aspects such as cost, data timeliness, and scalability.
| Feature | RAG | Fine-Tuning / Long Context Windows |
| Cost | Minimal, no training required | High, requires extensive training and updating |
| Data Timeliness | Data retrieved on-demand, ensuring currency | Data can quickly become outdated |
| Transparency | High, shows retrieved documents | Low, unclear how data influences outcomes |
| Scalability | High, easily integrates with various data sources | Limited, scaling up involves significant resources |
| Performance | Selective data retrieval enhances performance | Performance can degrade with larger context sizes |
| Adaptability | Can be tailored to specific tasks without retraining | Requires retraining for significant adaptations |

# Optimizing RAG Systems with Vector Databases
State-of-the-art LLMs can process millions of tokens simultaneously, but the complexity and constant evolution of data structures make it challenging for LLMs to manage heterogeneous enterprise data effectively. RAG addresses these challenges, although retrieval accuracy remains a major bottleneck for end-to-end performance. Whether it's the large context window of LLMs or RAG, the goal is to make the best use of big data and ensure the high efficiency of large-scale data processing.
Integrating LLMs with big data (opens new window) using advanced SQL vector databases like MyScaleDB (opens new window) enhances the effectiveness of LLMs and facilitates better intelligence extraction from big data. Additionally, it mitigates model hallucination, offers data transparency, and improves reliability. MyScaleDB, an open-source SQL vector database built on ClickHouse (opens new window) is tailored for large AI/RAG applications. Leveraging ClickHouse as its base and featuring the proprietary MSTG algorithm, MyScaleDB demonstrates superior performance managing large-scale data compared to other vector databases (opens new window).
LLM technology is changing the world, and the importance of long-term memory will persist. Developers of AI applications are always striving for the perfect balance between query quality and cost. When large enterprises put generative AI into production, they need to control costs while maintaining the best quality of response. RAG and vector databases remain important tools to achieve this goal.
You’re welcome to dive into MyScaleDB on GitHub (opens new window) or discuss more about LLMs or RAG in our Discord (opens new window).
This article is originally published on The New Stack. (opens new window)



