
Retrieval-Augmented Generation (RAG) (opens new window) systems have been designed to improve the response quality of a large language model (LLM). When a user submits a query, the RAG system extracts relevant information from a vector database and passes it to the LLM as context. The LLM then uses this context to generate a response for the user. This process significantly improves the quality of LLM responses with less “hallucination” (opens new window).
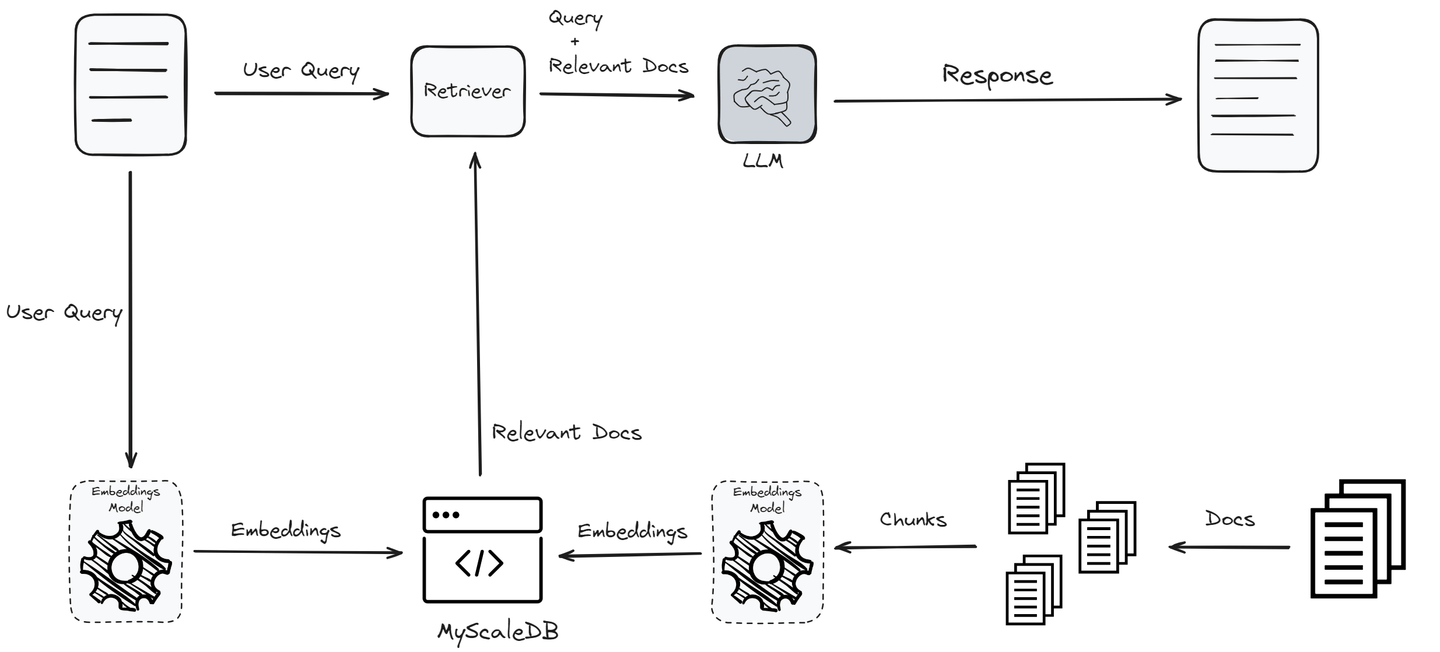
So, in the workflow above, there are two main components in a RAG system:
Retriever: It identifies the most relevant information from the vector database using the power of similarity search. This stage is the most critical part of any RAG system as it sets the foundation for the quality of the final output. The retriever searches a vector database to find documents relevant to the user query. It involves encoding the query and the documents into vectors and using similarity measures to find the closest matches.
Response generator: Once the relevant documents are retrieved, the user query and the retrieved documents are passed to the LLM model to generate a coherent, relevant, and informative response. The generator (LLM) takes the context provided by the retriever and the original query to generate an accurate response.
The effectiveness and performance of any RAG system significantly depend on these two core components: the retriever and the generator. The retriever must efficiently identify and retrieve the most relevant documents, while the generator should produce responses that are coherent, relevant, and accurate, using the retrieved information. Rigorous evaluation of these components is crucial to ensure optimal performance and reliability of the RAG model before deployment.
# Evaluating RAG
To evaluate an RAG system, we commonly use two kinds of evaluations:
- Retrieval Evaluation
- Response Evaluation
Unlike traditional machine learning techniques, where there are well-defined quantitative metrics (such as Gini, R-squared, AIC, BIC, confusion matrix, etc.), the evaluation of RAG systems is more complex. This complexity arises because the responses generated by RAG systems are unstructured text, requiring a combination of qualitative and quantitative metrics to assess their performance accurately.
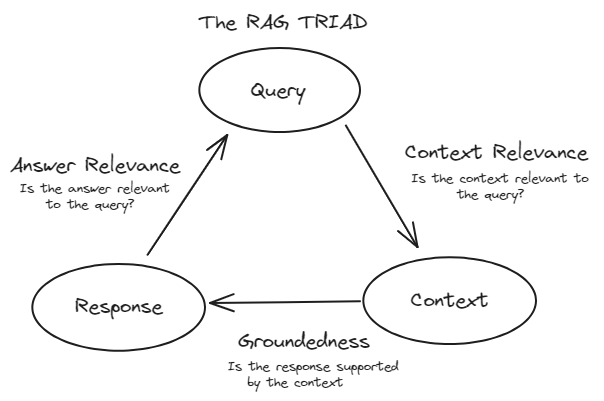
# TRIAD Framework
To effectively evaluate RAG systems, we commonly follow the TRIAD framework. This framework consists of three major components:
Context Relevance: This component evaluates the retrieval part of the RAG system. It evaluates how accurately the documents were retrieved from the large dataset. Metrics like precision, recall, MRR, and MAP are used here.
Faithfulness (Groundedness): This component falls under the response evaluation. It checks if the generated response is factually accurate and grounded in the retrieved documents. Methods such as human evaluation, automated fact-checking tools, and consistency checks are used to assess faithfulness.
Answer Relevance: This is also part of the Response Evaluation. It measures how well the generated response addresses the user's query and provides useful information. Metrics like BLEU, ROUGE, METEOR, and embedding-based evaluations are used.
# Retrieval Evaluation
Retrieval evaluations are applied to the retriever component of an RAG system, which typically uses a vector database. These evaluations measure how effectively the retriever identifies and ranks relevant documents in response to a user query. The primary goal of retrieval evaluations is to assess context relevance—how well the retrieved documents align with the user's query. It ensures that the context provided to the generation component is pertinent and accurate.

Each of the metrics offers a unique perspective on the quality of the retrieved documents and contributes to a comprehensive understanding of context relevance.
# Precision
Precision measures the accuracy of the retrieved documents. It is the ratio of the number of relevant documents retrieved to the total number of documents retrieved. It’s defined as:
This means that precision evaluates how many of the documents retrieved by the system are actually relevant to the user's query. For example, if the retriever retrieves 10 documents and 7 of them are relevant, the precision would be 0.7 or 70%.
Precision evaluates, "Out of all the documents that the system retrieved, how many were actually relevant?”
Precision is especially important when presenting irrelevant information can have negative consequences. For example, high precision in a medical information retrieval system is crucial because providing irrelevant medical documents could lead to misinformation and potentially harmful outcomes.
# Recall
Recall measures the comprehensiveness of the retrieved documents. It is the ratio of the number of relevant documents retrieved to the total number of relevant documents in the database for the given query. It’s defined as:
This means that recall evaluates how many of the relevant documents that exist in the database were successfully retrieved by the system.
Recall evaluates: "Out of all the relevant documents that exist in the database, how many did the system manage to retrieve?"
Recall is critical in situations where missing out on relevant information can be costly. For instance, in a legal information retrieval system, high recall is essential because failing to retrieve a relevant legal document could lead to incomplete case research and potentially affect the outcome of legal proceedings.
# Balance Between Precision and Recall
Balancing precision and recall is often necessary, as improving one can sometimes reduce the other. The goal is to find an optimal balance that suits the specific needs of the application. This balance is sometimes quantified using the F1 score, which is the harmonic mean of precision and recall:
# Mean Reciprocal Rank (MRR)
Mean Reciprocal Rank (MRR) is a metric that evaluates the effectiveness of the retrieval system by considering the rank position of the first relevant document. It is particularly useful when only the first relevant document is of primary interest. The reciprocal rank is the inverse of the rank at which the first relevant document is found. MRR is the average of these reciprocal ranks across multiple queries. The formula for MRR is:
Where Q is the number of queries and
MRR evaluates "On average, how quickly is the first relevant document retrieved in response to a user query?"
For example, in a RAG-based question-answering system, MRR is crucial because it reflects how quickly the system can present the correct answer to the user. If the correct answer appears at the top of the list more frequently, the MRR value will be higher, indicating a more effective retrieval system.
# Mean Average Precision (MAP)
Mean Average Precision (MAP) is a metric that evaluates the precision of retrieval across multiple queries. It takes into account both the precision of the retrieval and the order of the retrieved documents. MAP is defined as the mean of the average precision scores for a set of queries. To calculate the average precision for a single query, the precision is computed at each position in the ranked list of retrieved documents, considering only the top-K retrieved documents, where each precision is weighted by whether the document is relevant or not. The formula for MAP across multiple queries is:
Where ( Q ) is the number of queries, and
MAP evaluates, "On average, how precise are the top-ranked documents retrieved by the system across multiple queries?”
For example, in a RAG-based search engine, MAP is crucial because it considers the precision of the retrieval at different ranks, ensuring that relevant documents appear higher in the search results, which enhances the user experience by presenting the most relevant information first.
# An overview of the retrieval evaluations
- Precision: Quality of retrieved results.
- Recall: Completeness of retrieved results.
- MRR: How quickly the first relevant document is retrieved.
- MAP: Comprehensive evaluation combining precision and rank of relevant documents.
# Response Evaluation
Response evaluations are applied to the generation component of a system. These evaluations measure how effectively the system generates responses based on the context provided by the retrieved documents. We divide response evaluations into two types:
- Faithfulness (Groundedness)
- Answer Relevance
# Faithfulness (Groundedness)
Faithfulness evaluates whether the generated response is accurate and grounded in the retrieved documents. It ensures that the response does not contain hallucinations or incorrect information. This metric is crucial because it traces the generated response back to its source, ensuring the information is based on a verifiable ground truth. Faithfulness helps prevent hallucinations, where the system generates plausible-sounding but factually incorrect responses.
To measure faithfulness, the following methods are commonly used:
- Human Evaluation: Experts manually assess whether the generated responses are factually accurate and correctly referenced from the retrieved documents. This process involves checking each response against the source documents to ensure all claims are substantiated.
- Automated Fact-Checking Tools: These tools compare the generated response against a database of verified facts to identify inaccuracies. They provide an automated way to check the validity of the information without human intervention.
- Consistency Checks: These evaluate if the model consistently provides the same factual information across different queries. This ensures that the model is reliable and does not produce contradictory information.
# Answer Relevance
Answer relevance measures how well the generated response addresses the user's query and provides useful information.
# BLEU (Bilingual Evaluation Understudy)
BLEU measures the overlap between the generated response and a set of reference responses, focusing on the precision of n-grams. It is calculated by measuring the overlap of n-grams (contiguous sequences of n words) between the generated and reference responses. The formula for the BLEU score is:
Where ( BP ) is the brevity penalty to penalize short responses, ( P_n ) is the precision of n-grams, and ( w_n ) are the weights for each n-gram level. BLEU quantitatively measures how closely the generated response matches the reference response.
# ROUGE (Recall-Oriented Understudy for Gisting Evaluation)
ROUGE measures the overlap of n-grams, word sequences, and word pairs between the generated and reference responses, considering both recall and precision. The most common variant, ROUGE-N, measures the overlap of n-grams between the generated and reference responses. The formula for ROUGE-N is:
ROUGE evaluates both the precision and recall, providing a balanced measure of how much relevant content from the reference is present in the generated response.
# METEOR (Metric for Evaluation of Translation with Explicit ORdering)
METEOR considers synonymy, stemming, and word order to evaluate the similarity between the generated response and the reference responses. The formula for the METEOR score is:
Where $ F_{\text{mean}}$ is the harmonic mean of precision and recall, and
# Embedding-Based Evaluation
This method uses vector representations of words (embeddings) to measure the semantic similarity between the generated response and the reference responses. Techniques such as cosine similarity are used to compare the embeddings, providing an evaluation based on the meaning of the words rather than their exact matches.

# Tips and Tricks to optimize RAG systems
There are some fundamental tips and tricks that you can use to optimize your RAG systems:
- Use Re-Ranking Techniques: Re-ranking has been the most widely used technique to optimize the performance of any RAG system. It takes the initial set of retrieved documents and further ranks the most relevant ones based on their similarity. We can more accurately assess document relevance using techniques like cross-encoders and BERT-based re-rankers. This ensures that the documents provided to the generator are contextually rich and highly relevant, leading to better responses.
- Tune Hyperparameters: Regularly tuning hyperparameters like chunk size, overlap, and the number of top retrieved documents can optimize the performance of the retrieval component. Experimenting with different settings and evaluating their impact on retrieval quality can lead to better overall performance of the RAG system.
- Embedding Models: Selecting an appropriate embedding model is crucial for optimizing a RAG system's retrieval component. The right model, whether general-purpose or domain-specific, can significantly enhance the system's ability to accurately represent and retrieve relevant information. By choosing a model that aligns with your specific use case, you can improve the precision of similarity searches and the overall performance of your RAG system. Consider factors such as the model's training data, dimensionality, and performance metrics when making your selection.
- Chunking Strategies: Customizing chunk sizes and overlaps can greatly improve the performance of RAG systems by capturing more relevant information for the LLM. For example, Langchain's semantic chunking splits documents based on semantics, ensuring each chunk is contextually coherent. Adaptive chunking strategies that vary based on document types (such as PDFs, tables, and images) can help in retaining more contextually appropriate information.
# Role of Vector Databases in RAG Systems
Vector databases are integral to the performance of RAG systems. When a user submits a query, the RAG system's retriever component leverages the vector database to find the most relevant documents based on vector similarity. This process is crucial for providing the language model with the right context to generate accurate and relevant responses. A robust vector database ensures fast and precise retrieval, directly influencing the overall effectiveness and responsiveness of the RAG system.
MyScaleDB (opens new window) is a SQL vector database built on the high-performance ClickHouse (opens new window) database. ClickHouse offers advanced data handling features like column-oriented storage and vectorized query execution. MyScale’s Multi-Scale Tree Graph (MSTG) (opens new window) algorithm has outperformed other indexing methods with 390 QPS (Queries Per Second) on the LAION 5M dataset, achieving a 95% recall rate and maintaining an average query latency of 18ms with the s1.x1 pod. This unique algorithm boosts indexing and search efficiency by combining hierarchical tree clustering with graph traversal techniques, making it faster and more accurate. MSTG also cuts down on resource use and speeds up search operations compared to traditional methods like HNSW (Hierarchical Navigable Small World) and IVF (Inverted File). Additionally, MyScaleDB's compatibility with SQL and its powerful vector search capabilities make it easy for developers to integrate it into their existing workflows, using familiar SQL queries for complex vector operations.
# Conclusion
Developing an RAG system is not inherently difficult, but evaluating RAG systems is crucial for measuring performance, enabling continuous improvement, aligning with business objectives, balancing costs, ensuring reliability, and adapting to new methods. This comprehensive evaluation process helps in building a robust, efficient, and user-centric RAG system.
By addressing these critical aspects, vector databases serve as the foundation for high-performing RAG systems (opens new window), enabling them to deliver accurate, relevant, and timely responses while efficiently managing large-scale, complex data. MyScaleDB is featured with proprietary MSTG algorithm, SQL and Vector joint queries that can significantly enhance RAG system performance, making MyScaleDB an excellent choice for building RAG systems.




