
In this series on the Advanced RAG pipeline, we’ve discussed how other components like Embedding models, indexing methods and chunking techniques build the foundation of efficient systems. Now, let’s explore a very important part of this pipeline: vector search. And you can find the all the topics here:
Topics:
Vector Search Methods
The key capability of a database lies in its search performance. From web search to object identification, its applications are countless, and hence, a lot depends on the search efficiency, versatility and accuracy. A little bit slower or inaccurate (or limited) search can be the difference between a satisfied or never-to-return-again customer, and businesses are well aware of this.
Vector search is essential in modern retrieval systems. It powers semantic search and ensures that retrieved data matches the query contextually. The core idea behind vector search is to represent each item as a high-dimensional vector, where each dimension corresponds to a feature or characteristic of the item. The similarity between two items can then be measured as the distance between their vector representations.
# Brief Introduction of Vector Indexing
Indexing is the key driving force behind vector search. It is what makes searches fast, efficient, and meaningful. Before running any search on a table, it must first be indexed. This process organizes the data in a way that allows the search to retrieve relevant results quickly. So, let’s first focus on the "index (opens new window)".
Here are some considerations while adding an index:
- Indexes can only be created on vector columns (
Array(Float32)) or text columns. - For vector columns, it’s crucial to specify the maximum length of the array beforehand. This ensures consistency in the structure of the data and helps the index work efficiently.
- Indexes are primarily used in similarity searches, which means you need to define a similarity metric while creating the index. For example, you might choose
Cosinesimilarity, which is one of the most common metrics for comparing vectors.
Indexes are the backbone of efficient vector searches, as they drastically reduce the time and computational effort required to find the right data. Choosing the right indexing strategy and understanding these considerations can make all the difference in the performance of your system.
# Example
Adding an index in MyScale (opens new window) is just like how we add it for any SQL table. As an example, we define a table and add a vector column there.
CREATE TABLE test_float_vector
(
id UInt32,
data Array(Float32),
CONSTRAINT check_length CHECK length(data) = 128,
date Date,
label Enum8('person' = 1, 'building' = 2, 'animal' = 3)
)
ENGINE = MergeTree
ORDER BY id
As you can see, we have added the maximum length constraint as it is necessary before adding an index.
ALTER TABLE default.test_float_vector
ADD VECTOR INDEX data_index data
TYPE MSTG ('metric_type=Cosine');
And using the same SQL we use for the traditional relational db queries, we can fetch the most relevant documents to the search term ("What was the solution proposed to farmers problem by Levin?"). The search phrase needs to be converted into an embedding first. We can do it using any embedding model or service. After getting the embedding (in input_embedding ) we get the most relevant documents.

Note:
MyScale also provides EMBEDTEXT() function, which can be directly used (opens new window) in both Python (or other) interface and SQL.
# Indexing Algorithms
The above syntax isn’t unique but vector indexing (opens new window) works a bit differently behind the scenes. Usually, it employs clustering and is followed by some graph/tree of vectors for faster traversal. Choosing a suitable indexing algorithm can be an important factor for the searching efficiency, here are some popular indexing algorithms:
- Local Sensitivity Hashing (LSH): Locality-Sensitive Hashing (LSH) uses special hash functions to group similar data points into the same bucket. This process ensures that embeddings or vectors close to each other are more likely to collide in the same hash table. It allows for faster searches in high-dimensional spaces, making it ideal for approximate nearest neighbor tasks.
- Inverted File (IVF) (opens new window): Inverted File Indexing (IVF) works by clustering the vectors into groups. When a query vector is provided, the system calculates the distance of the query from the centers of all clusters. It then searches within the cluster that is closest to the query. However, since this search relies on the cluster centers (similar to k-Nearest Neighbors), a potential downside is that closer vectors in other clusters might be missed. Additionally, in some cases, multiple clusters may need to be searched for better results.
IVF also has several variants, such as IVF-Flat (opens new window) and IVF-PQ (opens new window), which offer different trade-offs in terms of performance and storage.
Note:
Choosing a suitable indexing algorithm becomes even more important in the context of how quickly vector databases grow with millions of vectors and hence every second saved is precious.
- Hierarchical Navigable Small Worlds (HNSW) (opens new window): HNSW works by building layers of graphs, which are progressively populated (i.e, topmost layer has the least number of nodes). This hierarchical layering means we don’t have to search too many nodes and hence it is quite fast. But making new graphs (whenever a new vector is added) can be quite time-consuming.
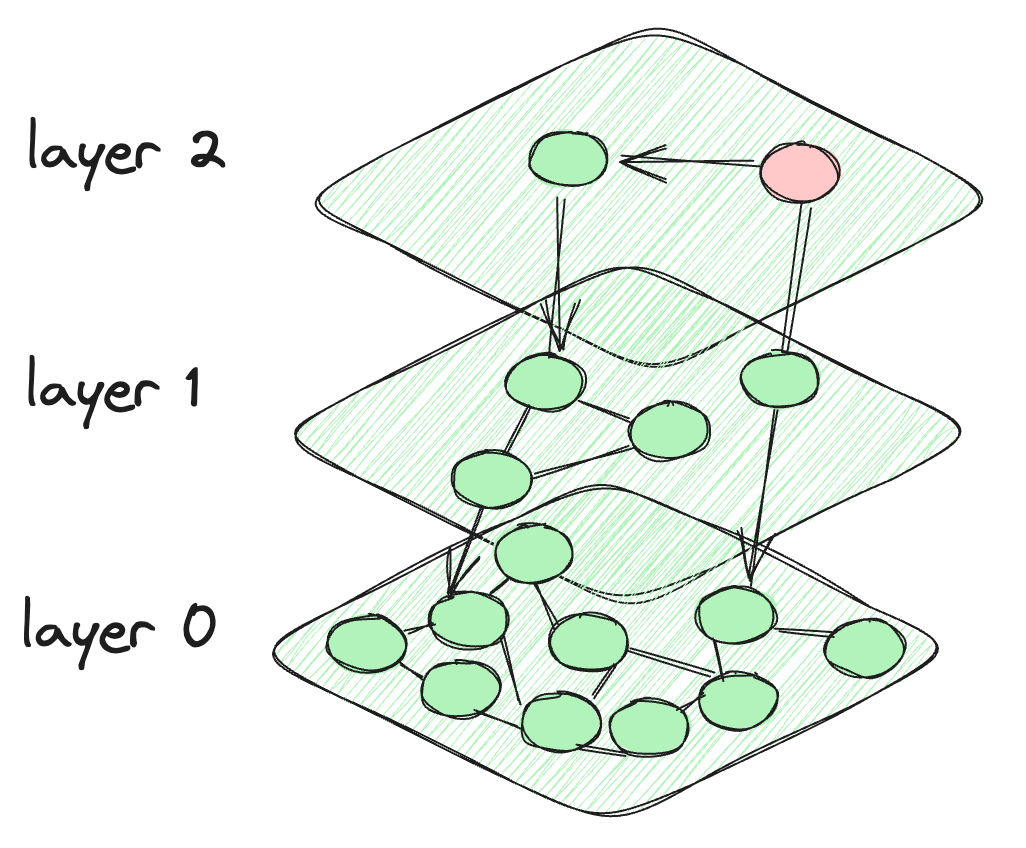
- Multi-Scale Tree Graph (MSTG) (opens new window): Both HNSW and IVF are quite good, but their performance issues start when scaling them for bigger datasets. Graph search is quite good at initial convergence, but struggles in filtered search, while tree search is good at filtered search, but slower. MSTG combines the both by using the combination of hierarchal graphs and trees.
Summarising it here as a table for the future (quick) reference:
| Sr No | Algorithm | Strengths | Areas for Improvement | Suitable for |
|---|---|---|---|---|
| 1 | LSH | High-dimensional data; parallelisation support | High memory usage; Slow | High-dimensional sparse data |
| 2 | IVF | Good for small and average data | Close clusters can lead to misses; | Datasets with distinguishable clusters |
| 3 | HNSW | Fast | Resource Intensive for new entries; Scalability | Verstaile |
| 4 | MSTG | Fast; Scalable; High accuracy | New and hence less mature | Verstaile |
# Basic Vector Search
Vector search is a sophisticated data retrieval technique that focuses on matching the contextual meanings of search queries and data entries, rather than simple text matching. To implement this technique, we must first convert both the search query and a specific column of the dataset into numerical representations, known as vector embeddings.
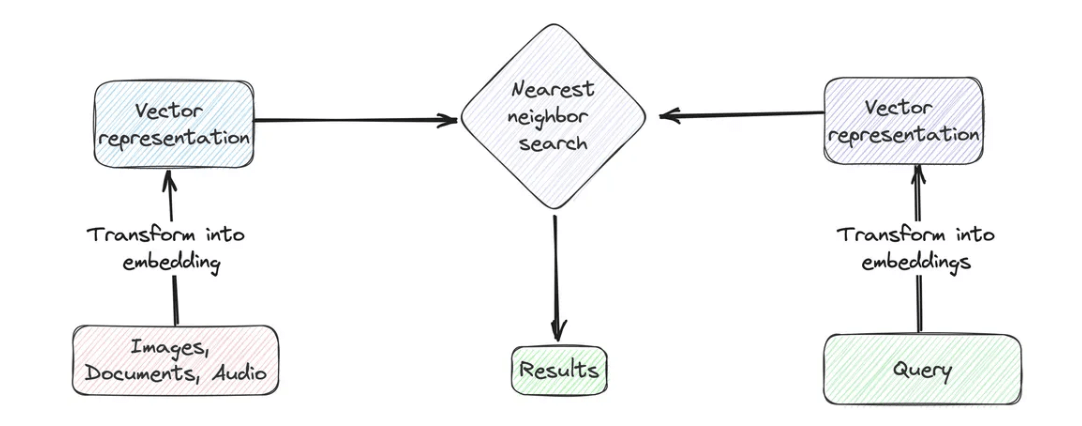
Then, calculate the distance (Cosine similarity or Euclidean distance) between the query vector and the vector embeddings in the database. Next, identify the closest or most similar entries based on these calculated distances. Lastly, we return the top-k results with the smallest distances to the query vector.
Note:
Semantic search builds on the basic definition of vector search to return more relevant results based on the meaning of text rather than exact terms. In practice, though, vector search and semantic search are often used interchangeably.
# Full-Text Search
Traditional SQL searches and even regular expressions are quite limited in taking either the exact term or a specific pattern for the comparison. This example will give an illustration. We are using SQL syntax to look up documents relevant to “Thanksgiving for vegans”.
| AND Condition | OR Condition |
|---|---|
SELECT
id,
title,
body
FROM
default.en_wiki_abstract
WHERE
body LIKE '%Thanksgiving%'
AND body LIKE '%vegans%'
ORDER BY
id
LIMIT
4;
| SELECT
id,
title,
body
FROM
default.en_wiki_abstract
WHERE
body LIKE '%Thanksgiving%'
OR body LIKE '%vegans%'
ORDER BY
id
LIMIT
4;
|
Applying AND search understandably doesn’t yield any result, while using OR operator broadens the scope by returning documents that contain either "Thanksgiving" or "vegans." While this approach retrieves results, not all documents may be highly relevant to both terms.

# The Limitations of Traditional SQL Search
Traditional SQL searches like these are rigid. They don't account for semantic similarities or variations in phrasing. For example, SQL treats "doctor applying anesthesia" and "doctor apply anesthesia" as completely different phrases, which means similar matches are often overlooked.
# How Full-Text Search Improves
In the former case, we perform searches based on the exact phrase, while in the latter, searches are conducted using keywords. Full-text search supports both methods, allowing for flexibility based on user preference. Unlike the rigid, default SQL search, full-text search accommodates some degree of variance in the text.
# How it works
Full-text search’s indexing works in these substeps.
- Tokenization : Tokenization is used to break down the text into smaller parts. In word tokenization, we take a text and it splits it into words, while sentence and character tokenizations split it on the sentence and character level respectively.
- Lemmatization/Stemming: Stemming and lemmatization break down the words into their “raw” form. For example, “playing” will be reduced to “play”, “children” to “child” and so on.
- Stopwords Removal: Some words like articles or prepositions contain lesser information and can be avoided by using this option. The default “English” stopword filter not only focuses on removing articles and prepositions, but some other words too, like “when”, “ourselves”, “my”, “doesn’t”, “not”, etc.
- Indexing : Once the text is preprocessed, it is stored in an inverted index.
Once the indexing is done, we can apply the search.
Scoring and Ranking: BM25 (Best Match 25) is a very commonly used algorithm. It ranks documents similar to how vector search ranks embeddings (or any general vectors) for similarity. BM25 is just an improved form of TF-IDF and depends on 3 factors: term frequency, inverse document frequency (rewarding rare terms) and document length normalization.
# Example
The full-text search index can be simply added by specifying the type fts. We can specify whether to choose lemmatization or stemming as well as the choice of stop word filters.
ALTER TABLE default.en_wiki_abstract
ADD INDEX body_idx body
TYPE fts('{"body":{"tokenizer":{"type":"stem", "stop_word_filters":["english"]}}}');
As you can see, it ranks the documents/text samples as per their similarity with the query.
SELECT
id,
title,
body,
TextSearch(body, 'thanksgiving for vegans') AS score
FROM default.en_wiki_abstract
ORDER BY score DESC
LIMIT 5;

# Hybrid Search
While full-text search provides some flexibility, it is still limited in its ability to find semantically similar text. For this, we need to rely on embeddings, which can capture the deeper semantic meaning of the text. On the other hand, full-text search has its own advantages, as it is great for basic keyword retrieval and text matching.
On the flip side, vector search (powered by embeddings) excels at cross-document semantic matching and deep understanding of semantics. However, it may lack efficiency when dealing with short text queries.
To get the best of both worlds, a hybrid search approach can be employed. By integrating full-text search and vector search, the hybrid approach can offer a more comprehensive and powerful search experience. Users can benefit from the precision of keyword-based retrieval as well as the deeper semantic understanding enabled by embeddings. This allows for more accurate and relevant search results, catering to a wide range of user needs and query types.
# Example
Let’s use an example to illustrate it further. We will continue using the same wiki_abstract_minitable for easier comparison. The full-text search index is added on body while the vector index on the respective embedding will further complement it.
ALTER TABLE default.wiki_abstract_mini
ADD INDEX body_idx (body)
TYPE fts('{"body":{"tokenizer":{"type":"stem", "stop_word_filters":["english"]}}}');
#Create Vector Index
ALTER TABLE default.wiki_abstract_mini
ADD VECTOR INDEX body_vec_idx body_vector
TYPE MSTG('metric_type=Cosine');
Since vector search is applied directly on the embeddings rather than the text, so we will use E5 large model here (via Hugging Face). Making a function will allow us to call it directly whenever we need to.
CREATE FUNCTION EmbeddingE5Large
ON CLUSTER '{cluster}' AS (x) -> EmbedText (
concat('query: ', x),
'HuggingFace',
'https://api-inference.huggingface.co/models/intfloat/multilingual-e5-large',
'hf_xxxx',
''
);
# Hybrid Search Function
HybridSearch() function is a search method that combines the strengths of vector search and text search. This approach not only enhances the understanding of long text semantics but also addresses the semantic shortcomings of vector search in the short-text domain.
SELECT
id,
title,
body,
HybridSearch('fusion_type=RSF', 'fusion_weight=0.6')(body_vector, body, EmbeddingE5Large('Charted by the BGLE'), ' BGLE') AS score
FROM default.wiki_abstract_mini
ORDER BY score DESC
LIMIT 5;

# Muiltimodal Search
Hybrid search provides us a combination of full-text and vector search. Multimodal search, however, takes it a step further by enabling searches across different types of data, such as images, videos, audio, and text.
This concept is based on contrastive learning (opens new window) and multimodal search works on a simple mechanism:
- A unified model like CLIP(Contrastive Language–Image Pretraining) (opens new window) processes various data types (like images or text) and converts them into embeddings.
- These embeddings are mapped into a single, shared vector space, making them comparable across data types.
- Regardless of the data’s original form, the embeddings closest to the query’s embedding are returned.
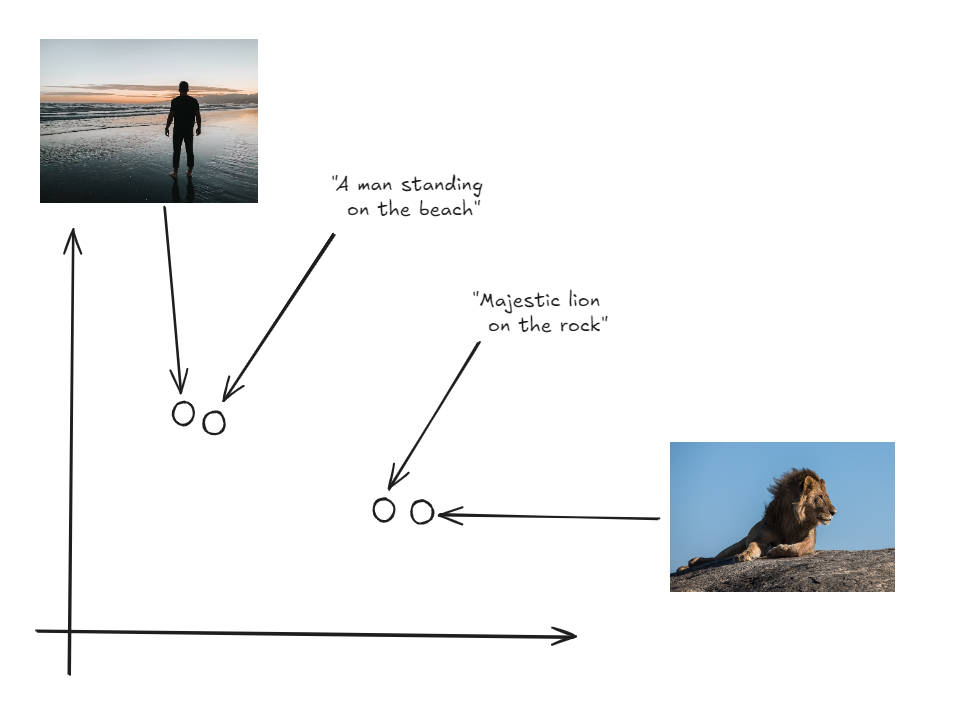
This approach allows us to retrieve diverse, relevant results—whether they are images, text, audio, or videos—based on a single query. For example, you can search for an image by providing a text description (opens new window) or find a video using an audio clip.
By aligning all data types into one vector space, multimodal search eliminates the need to combine separate results from different models. This also shows how powerful and flexible vector databases can be, helping to retrieve data from multiple types of sources seamlessly.
# Conclusion
Vector databases have revolutionized the way data is stored, providing not just enhanced speed but also immense utility across diverse domains such as artificial intelligence and big data analytics. And the cornerstone of this technology lies in the search capabilities.
MyScale provides 3 types of search, which we have covered: vector (opens new window), full-text (opens new window) and hybrid search (opens new window). By covering indexing algorithms and providing these diverse search functionalities, MyScale empowers users to tackle a wide range of data retrieval challenges across different domains and use cases. We hope the examples provided give you a good understanding of these search capabilities and how to leverage them effectively.



