
Imagine you're a software developer looking for database optimization techniques, especially to boost the efficiency of queries in large-scale databases. In a traditional SQL database, you might use keywords like "B-Tree indexing" or simply "Indexing" to find related blogs or articles. However, this keyword-based approach might overlook important blogs or articles that use different but related phrases, such as "SQL tuning" or "indexing strategies".
Consider another scenario where you're aware of the context but not the exact name of a specific technique. Traditional databases, being reliant on exact keyword matches, fall short in such situations as they cannot search based on context alone.
What we need, then, is a search technique that goes beyond simple keyword matching and delivers results based on semantic similarities. This is where vector search comes into play. Unlike traditional keyword matching techniques, vector search compares your query's semantics with the database entries, returning more relevant and accurate results.
In this blog, we'll discuss everything related to vector search, starting with the basic concepts and then moving onto more advanced techniques. Let’s begin by overviewing vector search.
# An Overview of Vector Search
Vector search is a sophisticated data retrieval technique that focuses on matching the contextual meanings of search queries and data entries, rather than simple text matching. To implement this technique, we must first convert both the search query and a specific column of the dataset into numerical representations, known as vector embeddings. Then, we calculate the distance (Cosine similarity or Euclidean distance) between the query vector and the vector embeddings in the database. Next, we then identify the closest or most similar entries based on these calculated distances. Lastly, we return the top-k results with smallest distances to the query vector.
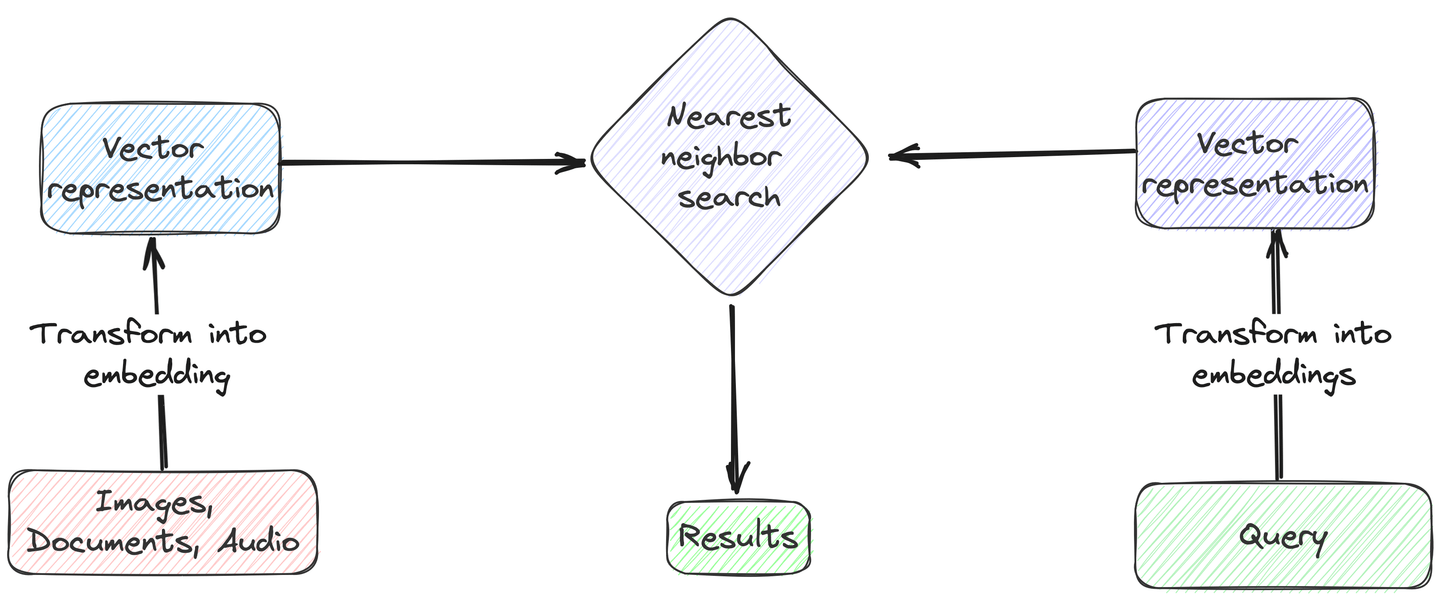
# Typical Scenarios for Vector Search
- Similarity Search: Use to find other vectors in the feature space that are similar to a given vector, widely applied in fields such as image, audio, and text analysis.
- Recommendation Systems: Achieve personalized recommendations by analyzing vector representations of users and items, such as movie, product, or music recommendations.
- Natural Language Processing: Search for semantic similarity in text data, supporting semantic search and relevance analysis.
- Question-Answering (QA) System: Search for related passages whose vector representations are most similar to the input question. The final answer can be generated with a Large Language Model (LLM) based on the question and the retrieved passages.
Brute-force vector search works really well for semantic search when the dataset is small and your queries are simple. However, its performance decreases as the dataset grows or the queries become more complex, resulting in a few drawbacks.
# Challenges in Implementing Vector Search
Let's discuss some of the issues associated with using a simple vector search, specifically when the dataset size increases:
- Performance: As discussed above, brute-force vector search computes the distance between a query vector and all the vectors in the database. It works well for smaller datasets but as the number of vectors increases to millions of entries, the search time and the computational cost to find the distance between the millions of entries grows.
- Scalability: Data is currently growing exponentially, making it very difficult for brute-force vector search to achieve results with the same speed and accuracy when querying massive datasets. This requires innovative ways to manage voluminous data while maintaining the same speed and accuracy.
- Combining with structured data: In simple applications, either a SQL query is used for querying structured data or a vector search for unstructured data, but applications often require the capabilities of both. Integrating these two can be technically challenging, especially when they are processed in different systems. When we utilize vector search and simultaneously apply SQL WHERE clauses for filtering, the query processing time increases as a result of the increased variety and size of data.
As a solution to these challenges, efficient vector indexing techniques are available.
# Common Vector Indexing Techniques
To address the challenges of large-scale vector data, various indexing techniques are employed to organize and facilitate efficient approximate vector searches. Let's explore some of these techniques.
# Hierarchical Navigable Small World (HSNW)
The HNSW algorithm leverages a multi-layered graph structure to store and efficiently search through vectors. At each layer, vectors are connected not only to other vectors on the same layer but also to vectors in the layers below. This structure allows for efficient exploration of nearby vectors while keeping the search space manageable. The top layers contain a small number of nodes, while the number of nodes increases exponentially as we descend the hierarchy. The bottom layer finally encompasses all data points in the database. This hierarchical design defines the distinctive architecture of the HNSW algorithm.
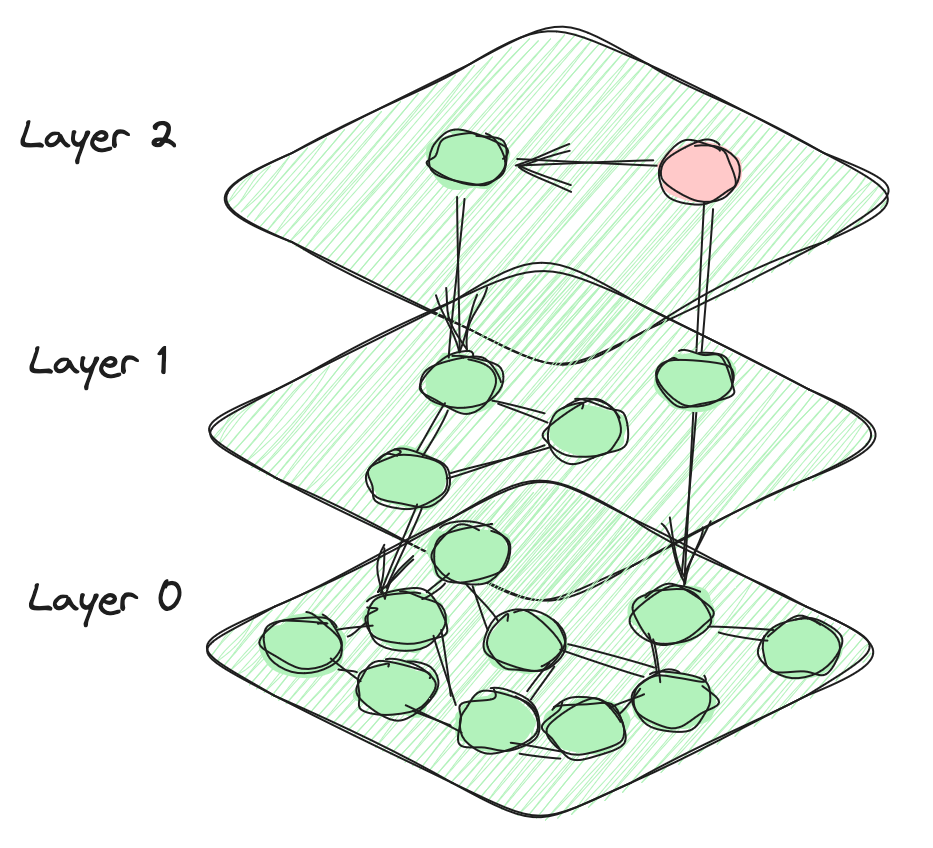
The search process begins with a selected vector, from which it computes the distances to connected vectors in both the current and preceding layers. This method is greedy, continuously progressing towards the vector nearest to the current position, iterating until a vector is identified that is the closest among all its connected vectors. While the HNSW index typically excels in straightforward vector searches, it demands considerable resources and requires extensive time for construction. Moreover, the accuracy and efficiency of filtered searches can substantially decline due to diminished graph connectivity under these conditions.
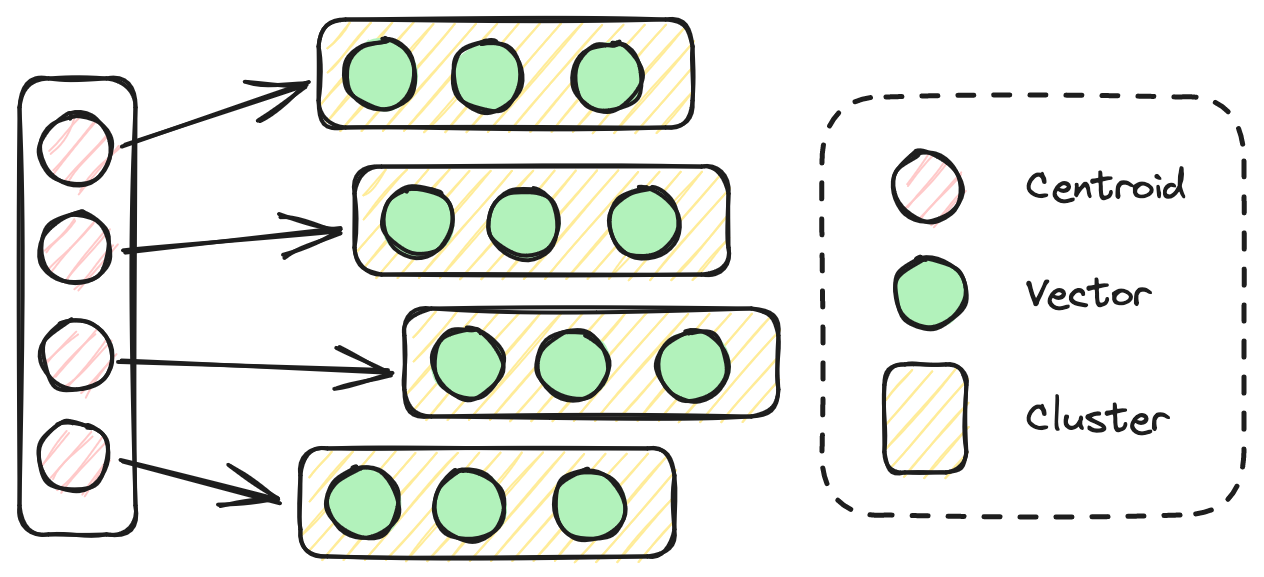
# Inverted Vector File (IVF) Index
The IVF index efficiently manages high-dimensional data searches by using cluster centroids as its inverted index. It segments vectors into clusters based on geometric proximity, with each cluster's centroid serving as a simplified representation. When searching for the most similar items to a query vector, the algorithm first identifies the centroids closest to the query. Then, it searches only within the associated list of vectors for those centroids, rather than the entire dataset. IVF take less time to build compared with HSNW, but also achieves lower accuracy and speed during the search process.


# MyScale in Action: Solutions and Practical Applications
As a SQL vector database, MyScale (opens new window) is designed to handle complex queries, allows fast data retrieval, and store large amounts of data efficiently. What makes it outperform specialized vector databases (opens new window) is it combines a fast SQL execution engine (based on ClickHouse) with our proprietary Multi-scale Tree Graph (MSTG) algorithm. MSTG combines the advantages of both tree and graph-based algorithms, allowing MyScale to build fast and search fast, and maintain speed and accuracy under different filtered search ratios, all while upholding resource and cost efficiency.
Now let's take a look at several practical applications where MyScale can be very helpful:
- Knowledge based QA applications: When developing a Question-answering (QA) system, MyScale is an ideal vector database with its ability self-query as well as flexible filtering for highly relevant results from your documents. Additionally, MyScale excels in scalability, allowing you to manage multiple users concurrently easily. To learn more, you can get help from our abstractive QA (opens new window) documentation. Additionally, you can utilize self-queries with advanced algorithms to improve the accuracy and speed of your search results.
- Large-scale AI chatbot: Developing a large-scale chatbot is a challenging task, especially when you must manage numerous users concurrently and ensure they are treated separately. Furthermore, the chatbot must provide accurate answers. MyScale has simplified building chatbots (opens new window) through its SQL-compatible role-based access control (opens new window) and large-scale multi-tenancy (opens new window) through data partitioning and filtered search, allowing you to manage multiple users.
- Image search: If you're creating a system that performs semantic or similar image search, MyScale can easily accommodate your growing image data while remaining performant and resource efficient. You can also write more complex SQL and vector join queries to match images by metadata or visual content. For more detailed information, see our image search project (opens new window) documentation.
In addition to these practical applications, by incorporating MyScale's SQL and vector capabilities, you can develop advanced recommendation systems (opens new window), object detection applications (opens new window), and many more.
# Conclusion
Vector search surpasses traditional term matching by interpreting the semantics within vectors embeddings. This approach is not only effective for text but also extends to images, audio, and various multi-modal unstructured data, as demonstrated in models like ImageBind (opens new window). However, this technology faces challenges such as computational and storage demands, as well as semantic fuzziness of high-dimensional vectors. MyScale solves these issues by innovatively merging SQL and vector search into a unified, high-performance, cost-effective system. This fusion enables a wide array of applications, from QA systems to AI chatbots and image searches, illustrating its versatility and efficiency.
Finally, welcome to connect with us on Twitter (opens new window) and Discord (opens new window). We love to hear and discuss your insights.



