
This article will conclude the advanced RAG (opens new window) series by turning our focus on document re-ranking. The first step of RAG (opens new window) is to retrieve multiple documents per query, and often, these documents are not relevant to the query. Hence, we require some external techniques to improve these results. In the end, a search is as powerful as the relevance of its results.
While applying the vector search, it is common to lose some semantic information, for a few reasons. For example, documents need to be broken down into smaller sub-documents, which can result in a loss of contextual information. Consequently, RAG models may struggle to effectively connect information across multiple retrieved documents. [1]
To address these challenges, we employ document re-ranking techniques within the RAG framework. There are a variety of methods that can be used to re-rank retrieved documents. Besides, if you are interested in the major key techniques involved in advanced RAG, you can explore them in the following list:
Topics:
Re-ranking Strategies
# What is Document Re-ranking
As the field of RAG continues to evolve, the role of reranking has emerged as a critical component in unlocking the full potential of RAG. Reranking is more than just a simple reorganization of retrieved results – it is a strategic process that can significantly enhance the relevance, diversity, and personalization of the information presented to users.
By leveraging additional signals and heuristics, the re-ranking stage of RAG can refine the initial document retrieval, ensuring the most pertinent and valuable data rises to the top. Moreover, re-ranking enables an iterative approach, progressively refining results for increasingly accurate and contextual outputs.
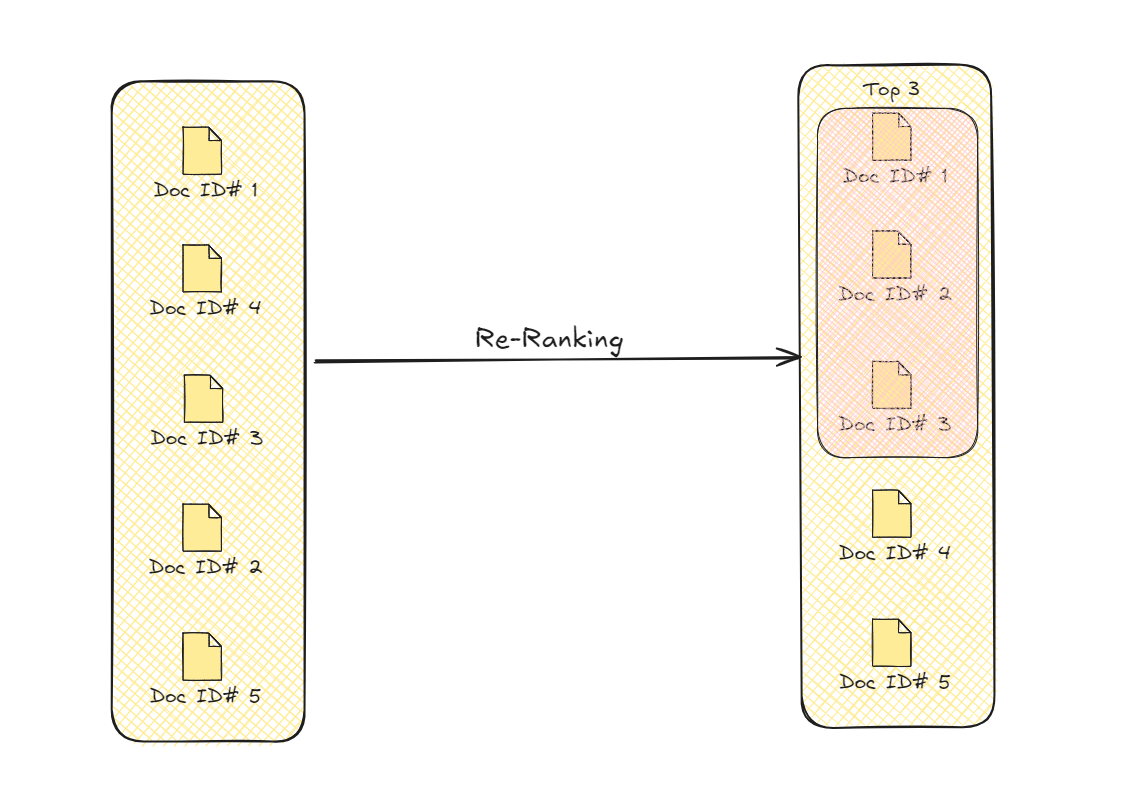
Re-ranking Documents
This process refines the retrieval results by prioritizing the documents that are more contextually appropriate for the query. This enhanced selection improves the overall quality and accuracy of the information that the model uses for generating its final output.
# Re-ranking with Transformers
Using transformer models (opens new window) for document re-ranking has a history even beyond the RAGs. In 2020, researchers adapted a pre-trained (seq2seq (opens new window)) transformer for document reranking. [2] This system takes a document as an input and returns whether it is relevant or not. After filtering out the relevant documents (i.e. “true” labeled), they reranked them using Softmax (opens new window) as a probability function.
Note:
Since these sequence-to-sequence models return a sequence too, it was modified to return only “true” or “false”.
# Using LLMs
Utilizing LLMs’ all-rounder capabilities to improve RAG is becoming common these days [4-7].
In one approach, researchers employed GPT-3 [4] to perform ranking purely using prompts and named it LRL (Listwise Reranker using LLM) (opens new window). The prompt they used was quite simple.

Sorted Re-ranked Documents
To increase the confidence of document relevance, a prompt was also used for the classification and named it PRL (Pointwise Reranker with an LLM) (opens new window).

Re-ranking with LLMs
In a more methodological approach [5], LLaMA (opens new window) is used for document reranking. This method (RankLLaMA (opens new window)) applies the ranking function on the retrieved documents as:
After applying the reranking function, we optimize it further using the InfoNCE loss (we have seen it before in MoCo for contrastive learning (opens new window)).
# Using Cross-encoders
Cross-encoders are another type of transformers that are commonly used for document reranking. As its name shows, the cross-encoder encodes both the query and (each) document and its output shows the cross-similarity/relevance between the two.

Re-ranking with Cross-encoders
As you can see, it's not feasible to cross-match every document with the query, so we shortlist the documents to take a smaller pool to cross-match from. There are two commonly used methods for pre-selection:
- Using bi-encoders
- Using sparse search methods (like BM25)
Cross-encoders (opens new window) have shown better performance over bi-encoders (opens new window) even before they were used in RAG due to their higher precision and improved contextual understanding. [6] It hardly comes as a surprise as they are now extensively used in document reranking for RAG. Here is a basic implementation using HuggingFace (opens new window) and PyTorch (opens new window).
from transformers import AutoTokenizer, AutoModelForSequenceClassification
import torch
tokenizer = AutoTokenizer.from_pretrained("cross-encoder/ms-marco-TinyBERT-L-6")
model = AutoModelForSequenceClassification.from_pretrained("cross-encoder/ms-marco-TinyBERT-L-6")
def ReRank(query, documents):
scores = []
for doc in documents:
inputs = tokenizer(query, doc, return_tensors="pt", padding=True, truncation=True, max_length=512)
with torch.no_grad():
outputs = model(**inputs)
scores.append(outputs.logits.squeeze().item())
rankedDocs = [doc for _, doc in sorted(zip(scores, documents), reverse=True)]
return rankedDocs
For a sample query, we can use it as:
query = "Which month is most suitable to visit Bali?"
#Assuming our documents in the docs variable as a list.
rankedDocs = ReRank(query, docs)
print(rankedDocs)
# Re-ranking Using Graphs
If you are an academic/scholar probably you would have used Litmaps (opens new window) and Connected Papers (opens new window), they are some good examples of graphs for semantic relationships. In these graphs, the documents are represented using nodes while edges represent their semantic relationships.
Litmaps and Connected Papers
After constructing this document graph, we use GNNs (opens new window) for massage-passing to update node features based on the neighbour nodes. It enables the model to learn from the context provided by related documents, enhancing its ability to identify relevant content even when direct connections to the query are weak.
# Abstract Meaning Representation (AMR)
While document graph construction and message-passing mechanism isn’t alien to GNN users, Abstract Meaning Representation (AMR) (opens new window) deserves some coverage.
AMR is a semantic graph representation of a sentence that captures its meaning abstractly, focusing on the concepts expressed and their relationships, rather than on syntactic details. AMR graphs have more structured semantic information compared to the general form of natural languageIt is particularly useful in graph-based document reranking for Retrieval-Augmented Generation (RAG) because it enables the encoding of rich semantic and structural information into the reranking process.
# G-RAG
There is a recently proposed method utilizing AMRs for reranking in RAG. G-RAG [1] In their setting, researchers build AMRs, take the top-100 documents and use them to build the document graph. Instead of traditional cross-entropy loss, G-RAG utilizes pairwise ranking loss to optimize for relevance ranking directly, which aligns better with the goals of reranking.
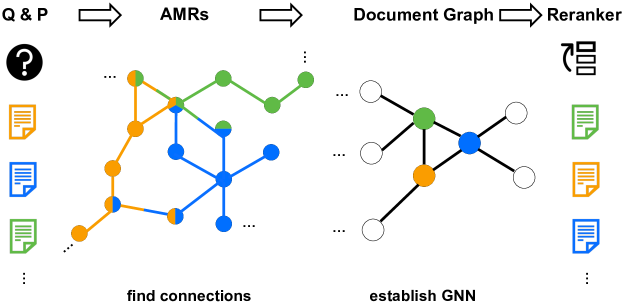
G-RAG
# MyScale's Two-stage Retrieval
MyScaleDB uses a two-stage retrieval process to optimize information retrieval. This process consists of:
Initial Retrieval: A broad set of potentially relevant documents is quickly retrieved using methods like vector search, which finds similar documents based on numerical representations (vectors).
Reranking: The retrieved documents are then refined and ranked using advanced techniques like cross-encoders to ensure the most relevant results are presented based on the user's query.
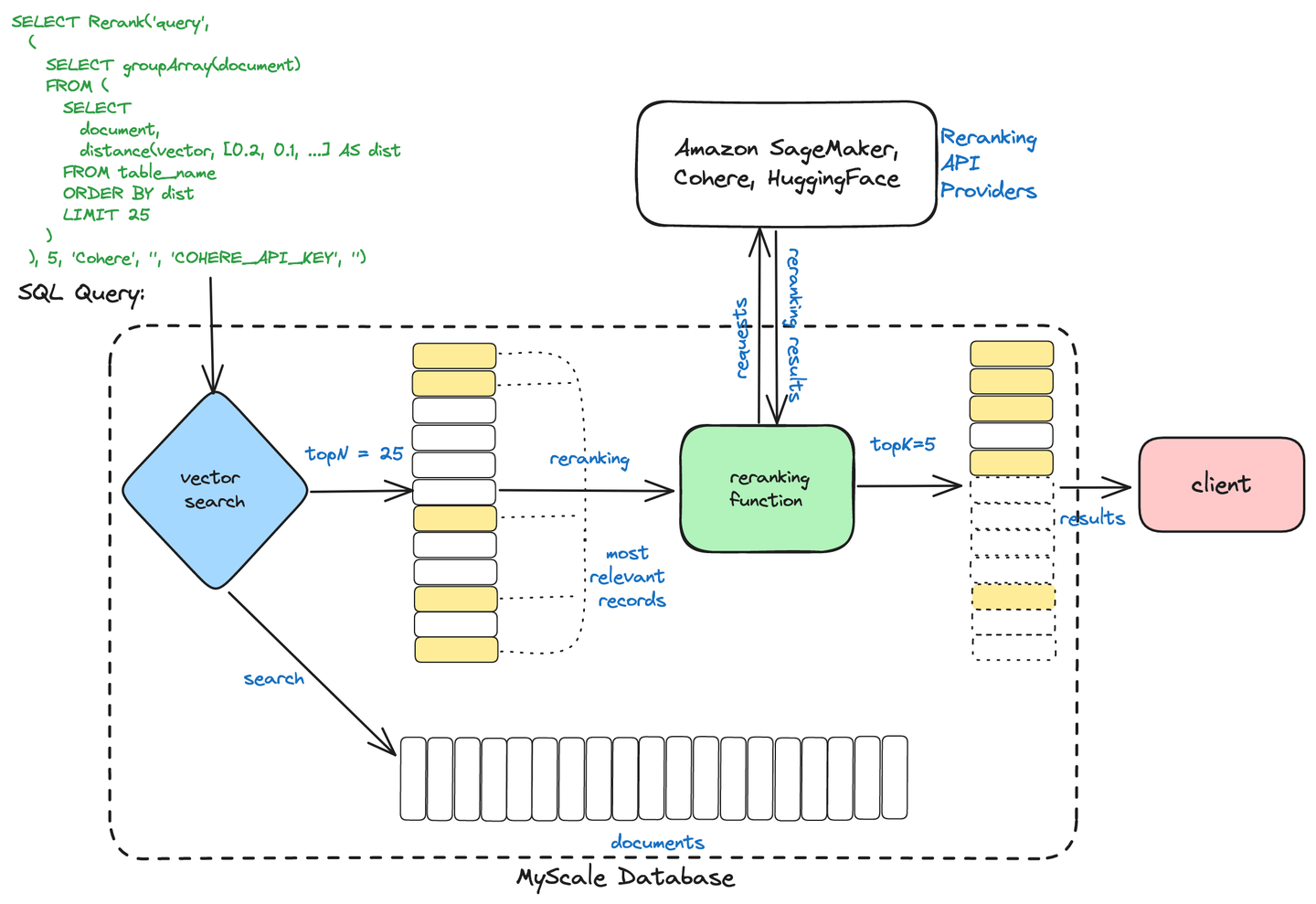
Two-stage Retrieval
This approach helps MyScaleDB deliver faster and more accurate search results by combining efficient retrieval with precise ranking.
Note:
You can read more about MyScale's Two-stage Retrieval (opens new window) in our blog.
# Re-ranking Using MyScale and Cohere
We will cap it off by using a full example. In this example we will use MyScale vector database to rerank documents in the RAG pipeline. For embeddings, we are using Cohere here, but it could be any other service like OpenAI or BedRock.
from langchain_community.vectorstores import MyScale, MyScaleSettings
from langchain_cohere import CohereEmbeddings
config = MyScaleSettings(host='host-name', port=443, username='your-user-name', password='your-passwd')
index = MyScale(CohereEmbeddings(), config)
Now we will add the documents into MyScale. Before adding into the db, they need to be (loaded and) splitted first.
from langchain_community.document_loaders import TextLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
documents = TextLoader("../file.txt").load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=100)
texts = text_splitter.split_documents(documents)
index.add_documents(texts)
As we have seen throughout, we needs a pool/subset of docs before applying the reranking, so fetch x documents subset
retriever = index.as_retriever(search_kwargs={"k": 20})
query = "Which place on earth is farthest away from its centre?"
docs = retriever.invoke(query)
Now we are set for reranking. We will initialize a language model with Cohere, set the reranker with CohereRerank, and combine it with the base retriever in a ContextualCompressionRetriever. This setup compresses and reranks the retrieval results, refining the output based on contextual relevance.
from langchain.retrievers.contextual_compression import ContextualCompressionRetriever
from langchain_cohere import CohereRerank
from langchain_community.llms import Cohere
llm = Cohere(temperature=0)
compressor = CohereRerank()
compression_retriever = ContextualCompressionRetriever(
base_compressor=compressor, base_retriever=retriever
)
compressed_docs = compression_retriever.invoke(
"Your-query-here"
)
After adding the re-ranker, the response of your RAG system will become more refined, which will not only improve the user experience but also reduce the number of tokens used.

# Conclusion
RAG's importance and immense applications are an open secret. As we conclude our in-depth exploration of the advanced techniques powering Retrieval Augmented Generation (RAG), it's clear that this field is rapidly evolving, pushing the boundaries of what's possible with data-driven intelligence. Throughout this blog series, we've delved into the intricacies of query optimization, vector search, chunking strategies, reranking methods, and a host of other essential components that form the foundation of modern RAG systems.
By mastering these advanced concepts, you've gained the knowledge and tools to unlock the full potential of your RAG initiatives. From optimizing your queries to deliver lightning-fast retrieval of relevant information, to leveraging cutting-edge vector indexing and search capabilities, you're now equipped to build RAG systems that can truly transform your decision-making processes.
As you move forward, remember that the field of Retrieval Augmented Generation is constantly evolving. Stay vigilant, continue learning, and explore innovative solutions like MyScale that can help you stay ahead of the curve. The future of data-driven intelligence is bright, and with the knowledge you've gained through this blog series, you're poised to be at the forefront of this exciting frontier.
If you want to dicuss more about the advanced RAG techniques, welcome to join our Discord (opens new window) to communicate with us.
# References
- Dong, J., Fatemi, B., Perozzi, B., Yang, L. F., & Tsitsulin, A. (2024). Don't Forget to Connect! Improving RAG with Graph-based Reranking. ArXiv. https://arxiv.org/abs/2405.18414
- Nogueira, R., Jiang, Z., & Lin, J. (2020). Document Ranking with a Pretrained Sequence-to-Sequence Model. ArXiv. https://arxiv.org/abs/2003.06713
- Dengrong Huang, Zizhong Wei, Aizhen Yue, Xuan Zhao, Zhaoliang Chen, Rui Li, Kai Jiang, Bingxin Chang, Qilai Zhang, Sijia Zhang, et al. Dsqa-llm: Domain-specific intelligent question answering based on large language model. In International Conference on AI-generated Content, pages 170–180. Springer, 2023.
- Xueguang Ma, Xinyu Zhang, Ronak Pradeep, and Jimmy Lin. Zero-shot listwise document reranking with a large language model. arXiv preprint arXiv:2305.02156, 2023
- Xueguang Ma, Liang Wang, Nan Yang, Furu Wei, and Jimmy Lin. Fine-tuning llama for multi-stage text retrieval. arXiv preprint arXiv:2310.08319, 2023.
- Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V., Goyal, N., Küttler, H., Lewis, M., Yih, W., Rocktäschel, T., Riedel, S., & Kiela, D. (2020). Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. NeurIPS. https://arxiv.org/abs/2005.11401
- Zhang, L., Zhang, Y., Long, D., Xie, P., Zhang, M., & Zhang, M. (2023). A Two-Stage Adaptation of Large Language Models for Text Ranking. ArXiv. https://arxiv.org/abs/2311.16720
- Cunxiang Wang, Zhikun Xu, Qipeng Guo, Xiangkun Hu, Xuefeng Bai, Zheng Zhang, and Yue Zhang. Exploiting Abstract Meaning Representation for open-domain question answering. In Anna Rogers, Jordan Boyd-Graber, and Naoaki Okazaki, editors, Findings of the Association for Computational Linguistics: ACL 2023, pages 2083–2096, Toronto, Canada, July 2023b. Association for Computational Linguistics. doi: 10.18653/v1/2023.findings-acl.131.



